Dealing with missing data in Python
Objective
We will be examining lightning strike data collected by the National Oceanic and Atmospheric Association (NOAA) for the month of August 2018. There are two datasets. The first includes five columns:
| date | center_point_geom | longitude | latitude | number_of_strikes |
The second dataset contains seven columns:
| date | zip_code | city | state | state_code | center_point_geom | number_of_strikes |
We want to combine the two datasets into a single dataframe that has all of the information from both datasets. Ideally, both datasets will have the same number of entries for the same locations on the same dates. If they don’t, we’ll investigate which data is missing.
Imports and Loading data
import pandas as pd
import numpy as np
import seaborn as sns
import datetime
from matplotlib import pyplot as plt
# Read in first dataset
df = pd.read_csv('eda_missing_data_dataset1.csv')
df.head()| date | center_point_geom | longitude | latitude | number_of_strikes | |
| 0 | 2018-08-01 | POINT(-81.6 22.6) | -81.6 | 22.6 | 48 |
| 1 | 2018-08-01 | POINT(-81.1 22.6) | -81.1 | 22.6 | 32 |
| 2 | 2018-08-01 | POINT(-80.9 22.6) | -80.9 | 22.6 | 118 |
| 3 | 2018-08-01 | POINT(-80.8 22.6) | -80.8 | 22.6 | 69 |
| 4 | 2018-08-01 | POINT(-98.4 22.8) | -98.4 | 22.8 | 44 |
df.shape(717530, 5)
# Read in second dataset
df_zip = pd.read_csv('eda_missing_data_dataset2.csv')
df_zip.head()| date | zip_code | city | state | state_code | center_point_geom | number_of_strikes | |
| 0 | 2018-08-08 | 3281 | Weare | New Hampshire | NH | POINT(-71.7 43.1) | 1 |
| 1 | 2018-08-14 | 6488 | Heritage Village CDP | Connecticut | CT | POINT(-73.2 41.5) | 3 |
| 2 | 2018-08-16 | 97759 | Sisters city, Black Butte Ranch CDP | Oregon | OR | POINT(-121.4 44.3) | 3 |
| 3 | 2018-08-18 | 6776 | New Milford CDP | Connecticut | CT | POINT(-73.4 41.6) | 48 |
| 4 | 2018-08-08 | 1077 | Southwick | Massachusetts | MA | POINT(-72.8 42) | 2 |
df_zip.shape(323700, 7)
Joining data
This dataset has less than half the number of rows as the first one. Let’s find out which ones are, by using the merge method.
# Left-join the two datasets
df_joined = df.merge(df_zip, how='left', on=['date','center_point_geom'])
df_joined.head()| date | center_point_geom | longitude | latitude | number_of_strikes_x | zip_code | city | state | state_code | number_of_strikes_y | |
| 0 | 2018-08-01 | POINT(-81.6 22.6) | -81.6 | 22.6 | 48 | NaN | NaN | NaN | NaN | NaN |
| 1 | 2018-08-01 | POINT(-81.1 22.6) | -81.1 | 22.6 | 32 | NaN | NaN | NaN | NaN | NaN |
| 2 | 2018-08-01 | POINT(-80.9 22.6) | -80.9 | 22.6 | 118 | NaN | NaN | NaN | NaN | NaN |
| 3 | 2018-08-01 | POINT(-80.8 22.6) | -80.8 | 22.6 | 69 | NaN | NaN | NaN | NaN | NaN |
| 4 | 2018-08-01 | POINT(-98.4 22.8) | -98.4 | 22.8 | 44 | NaN | NaN | NaN | NaN | NaN |
The unique columns of each original dataframe also appear in the merged dataframe. But both original dataframes had another column ‘number_of_strikes’ that had the same name in both dataframes and was not indicated as a key. Pandas handles this by adding both columns to the new dataframe.
# Get descriptive statistics of the joined dataframe
df_joined.describe()| longitude | latitude | number_of_strikes_x | zip_code | number_of_strikes_y | |
| count | 717530.000000 | 717530.000000 | 717530.000000 | 323700.000000 | 323700.000000 |
| mean | -90.875445 | 33.328572 | 21.637081 | 57931.958996 | 25.410587 |
| std | 13.648429 | 7.938831 | 48.029525 | 22277.327411 | 57.421824 |
| min | -133.900000 | 16.600000 | 1.000000 | 1002.000000 | 1.000000 |
| 25% | -102.800000 | 26.900000 | 3.000000 | 38260.750000 | 3.000000 |
| 50% | -90.300000 | 33.200000 | 6.000000 | 59212.500000 | 8.000000 |
| 75% | -80.900000 | 39.400000 | 21.000000 | 78642.000000 | 24.000000 |
| max | -43.800000 | 51.700000 | 2211.000000 | 99402.000000 | 2211.000000 |
The count information confirms that the new dataframe is missing some data.
Checking missing data
Now let’s check how many missing state locations we have by using isnull() to create a Boolean mask that we’ll apply to df_joined.
# Create a new df of just the rows that are missing data
df_null_geo = df_joined[pd.isnull(df_joined.state_code)]
df_null_geo.shape(393830, 10)
(Note that using the state_code column to create this mask is an arbitrary decision. We could have selected zip_code, city, or state instead and gotten the same results.)
Or we could quickly use info() method to check non-null values.
# Get non-null counts on merged dataframe
df_joined.info()<class 'pandas.core.frame.DataFrame'>
Int64Index: 717530 entries, 0 to 717529
Data columns (total 10 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 date 717530 non-null object
1 center_point_geom 717530 non-null object
2 longitude 717530 non-null float64
3 latitude 717530 non-null float64
4 number_of_strikes_x 717530 non-null int64
5 zip_code 323700 non-null float64
6 city 323700 non-null object
7 state 323700 non-null object
8 state_code 323700 non-null object
9 number_of_strikes_y 323700 non-null float64
dtypes: float64(4), int64(1), object(5)
memory usage: 60.2+ MB
df_null_geo.head()| date | center_point_geom | longitude | latitude | number_of_strikes_x | zip_code | city | state | state_code | number_of_strikes_y | |
| 0 | 2018-08-01 | POINT(-81.6 22.6) | -81.6 | 22.6 | 48 | NaN | NaN | NaN | NaN | NaN |
| 1 | 2018-08-01 | POINT(-81.1 22.6) | -81.1 | 22.6 | 32 | NaN | NaN | NaN | NaN | NaN |
| 2 | 2018-08-01 | POINT(-80.9 22.6) | -80.9 | 22.6 | 118 | NaN | NaN | NaN | NaN | NaN |
| 3 | 2018-08-01 | POINT(-80.8 22.6) | -80.8 | 22.6 | 69 | NaN | NaN | NaN | NaN | NaN |
| 4 | 2018-08-01 | POINT(-98.4 22.8) | -98.4 | 22.8 | 44 | NaN | NaN | NaN | NaN | NaN |
Understanding what data is missing
Now that we’ve merged all of our data together and isolated the rows with missing data, we can better understand what data is missing by plotting the longitude and latitude of locations that are missing city, state, and zip code data.
# Create new df of just latitude, longitude, and number of strikes and group by latitude and longitude
top_missing = df_null_geo[['latitude','longitude','number_of_strikes_x']]
.groupby(['latitude','longitude'])
.sum().sort_values('number_of_strikes_x',ascending=False).reset_index()
top_missing.head(10)| latitude | longitude | number_of_strikes_x | |
| 0 | 22.4 | -84.2 | 3841 |
| 1 | 22.9 | -82.9 | 3184 |
| 2 | 22.4 | -84.3 | 2999 |
| 3 | 22.9 | -83.0 | 2754 |
| 4 | 22.5 | -84.1 | 2746 |
| 5 | 22.5 | -84.2 | 2738 |
| 6 | 22.3 | -81.0 | 2680 |
| 7 | 22.9 | -82.4 | 2652 |
| 8 | 22.9 | -82.3 | 2618 |
| 9 | 22.3 | -84.3 | 2551 |
Plotting the missing data
Let’s import plotly to reduce the size of the dataframe as we create a geographic scatter plot. Express is a helpful package that speeds up coding by doing a lot of the back-end work for us. If we don’t use express for this particular data set which has hundreds of thousands of points to plot our run-cell times could be long or the code could even break.
import plotly.express as px # Be sure to import express
# reduce size of db otherwise it could break
fig = px.scatter_geo(top_missing[top_missing.number_of_strikes_x>=300], # Input Pandas DataFrame
lat="latitude", # DataFrame column with latitude
lon="longitude", # DataFrame column with latitude
size="number_of_strikes_x") # Set to plot size as number of strikes
fig.update_layout(
title_text = 'Missing data', # Create a Title
)
fig.show()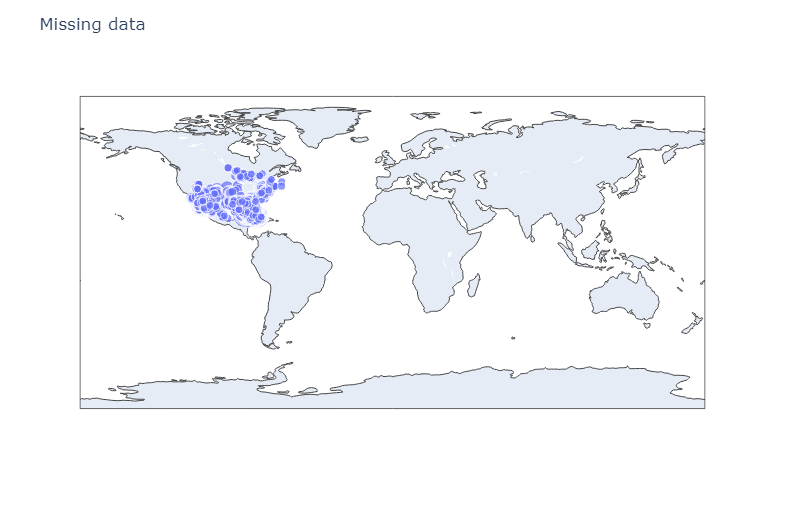
(The image above is static, but when working in a Python notebook like Jupyter the above code brings a dynamic one.)
Let’s scale the map down to only the geographic area that we are interested in, the United States.
import plotly.express as px # Be sure to import express
fig = px.scatter_geo(top_missing[top_missing.number_of_strikes_x>=300], # Input Pandas DataFrame
lat="latitude", # DataFrame column with latitude
lon="longitude", # DataFrame column with latitude
size="number_of_strikes_x") # Set to plot size as number of strikes
fig.update_layout(
title_text = 'Missing data', # Create a Title
geo_scope='usa', # Plot only the USA instead of globe
)
fig.show()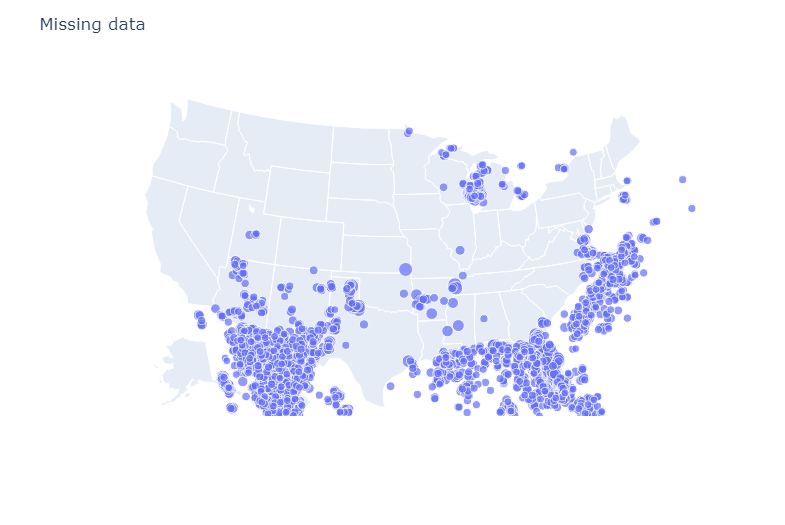
The resulting map shows a majority of these missing values cropping up along the borders or in spots over bodies of water like lakes, the ocean, or the Gulf of Mexico. Given that the missing data were in the state abbreviations and zip code columns, it does make sense why those data points were left blank.
But we can also see some other locations with missing data that are not over bodies of water. These types of missing data, latitude and longitude on land are the kind of missing data we would want to reach out to the NOA A about.