Introduction
We will be working with the unicorn companies dataset, once again. Our tasks would be as follows.
The investor has asked us to provide them with the following data:
- Companies in the hardware industry based in Beijing, San Francisco, and London.
- Companies in the artificial intelligence industry based in London.
- A list of the top 20 countries sorted by sum of company valuations in each country, excluding United States, China, India, and United Kingdom.
- A global valuation map of all countries except United States, China, India, and United Kingdom.
1. Imports
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import plotly.express as px
import seaborn as sns
# Read the data into a dataframe
df_companies = pd.read_csv('Unicorn_Companies.csv')2. Data exploration
df_companies.head()| Company | Valuation | Date Joined | Industry | City | Country/Region | Continent | Year Founded | Funding | Select Investors | |
| 0 | Bytedance | $180B | 4/7/17 | Artificial intelligence | Beijing | China | Asia | 2012 | $8B | Sequoia Capital China, SIG Asia Investments, S… |
| 1 | SpaceX | $100B | 12/1/12 | Other | Hawthorne | United States | North America | 2002 | $7B | Founders Fund, Draper Fisher Jurvetson, Rothen… |
| 2 | SHEIN | $100B | 7/3/18 | E-commerce & direct-to-consumer | Shenzhen | China | Asia | 2008 | $2B | Tiger Global Management, Sequoia Capital China… |
| 3 | Stripe | $95B | 1/23/14 | Fintech | San Francisco | United States | North America | 2010 | $2B | Khosla Ventures, LowercaseCapital, capitalG |
| 4 | Klarna | $46B | 12/12/11 | Fintech | Stockholm | Sweden | Europe | 2005 | $4B | Institutional Venture Partners, Sequoia Capita… |
df_companies.shape(1074, 10)
df_companies.info()<class 'pandas.core.frame.DataFrame'>
RangeIndex: 1074 entries, 0 to 1073
Data columns (total 10 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 Company 1074 non-null object
1 Valuation 1074 non-null object
2 Date Joined 1074 non-null object
3 Industry 1074 non-null object
4 City 1058 non-null object
5 Country/Region 1074 non-null object
6 Continent 1074 non-null object
7 Year Founded 1074 non-null int64
8 Funding 1074 non-null object
9 Select Investors 1073 non-null object
dtypes: int64(1), object(9)
memory usage: 84.0+ KB
Columns City and Select Investors contain fewer non-null values than the total number of rows in the dataset, which indicates that they are missing values.
df_companies.describe()| Year Founded | |
| count | 1074.000000 |
| mean | 2012.895717 |
| std | 5.698573 |
| min | 1919.000000 |
| 25% | 2011.000000 |
| 50% | 2014.000000 |
| 75% | 2016.000000 |
| max | 2021.000000 |
The oldest company in the list was founded in 1919. This is the minimum value in Year Funded.
Data Preprocessing
Let’s create a column for just the year each company became a unicorn company.
# Create a new column `Year Joined`
df_companies['Year_Joined'] = pd.to_datetime(df_companies['Date Joined']).dt.yearFor each country, we want to calculate the sum of all valuations of companies from that country. However, we’ll need to first prepare the data. The Valuation column needs to be converted to a numeric datatype.
We’ll achieve this by defining a function and using the string strip() method. This method is applied to a string. Its argument is a string that contains all the characters that you want to remove from the beginning and end of a given string—in any order.
The specified characters will be removed until a valid character is encountered. This process is applied moving forward from the beginning of the string and also moving in reverse from the end of the string, thus removing unwanted beginning and trailing characters.
Example:
[IN]: my_string = '#....... Section 3.2.1 Issue #32 .......'
my_string = my_string.strip('.#! ')
print(my_string)
[OUT]: 'Section 3.2.1 Issue #32'
Note that we must reassign the result back to a variable or else the change will not be permanent.
# Define the `str_to_num()` function
def str_to_num(x):
x = x.strip('$B')
x = int(x)
return xNow we can create a new column that represents the Valuation column as an integer value. To do this, we’ll use the series method apply() to apply the str_to_num() function to the Valuation column.
apply() is a method that can be used on a DataFrame or Series object. In this case, we’re using it on the Valuation series. The method accepts a function as an argument and applies that function to each value in the series.
Example:
[IN]: def square(x):
return x ** 2
my_series = pd.Series([0, 1, 2, 3])
my_series
[OUT]: 0 0
1 1
2 2
3 3
dtype: int64
[IN]: my_series = my_series.apply(square)
my_series
[OUT]: 0 0
1 1
2 4
3 9
dtype: int64
Notice that the function passed as an argument to the apply() method does not have parentheses. It’s just the function name.
# Apply the `str_to_num()` function to the `Valuation` column
# and assign the result back to a new column called `valuation_num`
df_companies['valuation_num'] = df_companies['Valuation'].apply(str_to_num)
df_companies[['Valuation', 'valuation_num']].head()| Valuation | valuation_num | |
| 0 | $180B | 180 |
| 1 | $100B | 100 |
| 2 | $100B | 100 |
| 3 | $95B | 95 |
| 4 | $46B | 46 |
Find missing values
The unicorn companies dataset is fairly clean, with few missing values.
# Find the number of missing values in each column in this dataset.
df_companies.isna().sum()Company 0
Valuation 0
Date Joined 0
Industry 0
City 16
Country/Region 0
Continent 0
Year Founded 0
Funding 0
Select Investors 1
Year_Joined 0
valuation_num 0
dtype: int64
There is a single missing value in the Select Investors column and 16 missing cities. There are no missing values in other columns.
Review rows with missing values
Before dealing with missing values, it’s important to understand the nature of the missing value that is being filled. That’s why we’ll display all rows with missing values from df_companies in 3 steps.
# Step 1: Apply the `isna()` method to the `df_companies` dataframe
# and assign back to `mask`
mask = df_companies.isna()
mask.tail()| Company | Valuation | Date Joined | Industry | City | Country/Region | Continent | Year Founded | Funding | Select Investors | Year_Joined | valuation_num | |
| 1069 | False | False | False | False | False | False | False | False | False | False | False | False |
| 1070 | False | False | False | False | False | False | False | False | False | False | False | False |
| 1071 | False | False | False | False | False | False | False | False | False | False | False | False |
| 1072 | False | False | False | False | False | False | False | False | False | False | False | False |
| 1073 | False | False | False | False | False | False | False | False | False | False | False | False |
Now we’ll need to go from this dataframe of Boolean values to a dataframe of just the rows of df_companies that contain at least one NaN value. This means that we need a way to find the indices of the rows of the Boolean dataframe that contain at least one True value, then extract those indices from df_companies.
We can do this using the any() method for DataFrame objects. This method returns a Boolean Series indicating whether any value is True over a specified axis.
Example:
df =
A B C
0 0 a 10
1 False 0 1
2 NaN NaN NaN
[IN]: df.any(axis=0)
[OUT]: A False
B True
C True
dtype: bool
[IN]: df.any(axis=1)
[OUT]: 0 True
1 True
2 False
dtype: bool
Note that 0, False, and NaN are considered False and anything else is considered True.
# Step 2: Apply the `any()` method to `mask`
# and assign the results back to `mask`
mask = mask.any(axis=1)
mask.head()0 False 1 False 2 False 3 False 4 False dtype: bool
Because mask is now a series of Boolean values, we can use it as a Boolean mask. We’ll apply the Boolean mask to the df_companies dataframe to return a filtered dataframe containing just the rows that contain a missing value.
# Step 3: Apply `mask` as a Boolean mask to `df_companies`
# and assign results to `df_missing_rows`
df_missing_rows = df_companies[mask]
df_missing_rows| Company | Valuation | Date Joined | Industry | City | Country/Region | Continent | Year Founded | Funding | Select Investors | Year_Joined | valuation_num | |
| 12 | FTX | $32B | 7/20/21 | Fintech | NaN | Bahamas | North America | 2018 | $2B | Sequoia Capital, Thoma Bravo, Softbank | 2021 | 32 |
| 170 | HyalRoute | $4B | 5/26/20 | Mobile & telecommunications | NaN | Singapore | Asia | 2015 | $263M | Kuang-Chi | 2020 | 4 |
| 242 | Moglix | $3B | 5/17/21 | E-commerce & direct-to-consumer | NaN | Singapore | Asia | 2015 | $471M | Jungle Ventures, Accel, Venture Highway | 2021 | 3 |
| 251 | Trax | $3B | 7/22/19 | Artificial intelligence | NaN | Singapore | Asia | 2010 | $1B | Hopu Investment Management, Boyu Capital, DC T… | 2019 | 3 |
| 325 | Amber Group | $3B | 6/21/21 | Fintech | NaN | Hong Kong | Asia | 2015 | $328M | Tiger Global Management, Tiger Brokers, DCM Ve… | 2021 | 3 |
| 382 | Ninja Van | $2B | 9/27/21 | Supply chain, logistics, & delivery | NaN | Singapore | Asia | 2014 | $975M | B Capital Group, Monk’s Hill Ventures, Dynamic… | 2021 | 2 |
| 541 | Advance Intelligence Group | $2B | 9/23/21 | Artificial intelligence | NaN | Singapore | Asia | 2016 | $536M | Vision Plus Capital, GSR Ventures, ZhenFund | 2021 | 2 |
| 629 | LinkSure Network | $1B | 1/1/15 | Mobile & telecommunications | Shanghai | China | Asia | 2013 | $52M | NaN | 2015 | 1 |
| 811 | Carousell | $1B | 9/15/21 | E-commerce & direct-to-consumer | NaN | Singapore | Asia | 2012 | $288M | 500 Global, Rakuten Ventures, Golden Gate Vent… | 2021 | 1 |
| 848 | Matrixport | $1B | 6/1/21 | Fintech | NaN | Singapore | Asia | 2019 | $100M | Dragonfly Captial, Qiming Venture Partners, DS… | 2021 | 1 |
| 880 | bolttech | $1B | 7/1/21 | Fintech | NaN | Singapore | Asia | 2018 | $210M | Mundi Ventures, Doqling Capital Partners, Acti… | 2021 | 1 |
| 889 | Carro | $1B | 6/14/21 | E-commerce & direct-to-consumer | NaN | Singapore | Asia | 2015 | $595M | SingTel Innov8, Alpha JWC Ventures, Golden Gat… | 2021 | 1 |
| 893 | Cider | $1B | 9/2/21 | E-commerce & direct-to-consumer | NaN | Hong Kong | Asia | 2020 | $140M | Andreessen Horowitz, DST Global, IDG Capital | 2021 | 1 |
| 980 | NIUM | $1B | 7/13/21 | Fintech | NaN | Singapore | Asia | 2014 | $285M | Vertex Ventures SE Asia, Global Founders Capit… | 2021 | 1 |
| 986 | ONE | $1B | 12/8/21 | Internet software & services | NaN | Singapore | Asia | 2011 | $515M | Temasek, Guggenheim Investments, Qatar Investm… | 2021 | 1 |
| 994 | PatSnap | $1B | 3/16/21 | Internet software & services | NaN | Singapore | Asia | 2007 | $352M | Sequoia Capital China, Shunwei Capital Partner… | 2021 | 1 |
| 1061 | WeLab | $1B | 11/8/17 | Fintech | NaN | Hong Kong | Asia | 2013 | $871M | Sequoia Capital China, ING, Alibaba Entreprene… | 2017 | 1 |
Twelve of the 17 rows with missing values are for companies from Singapore.
At this point, we can ask the business users for insight into the causes of missing values and, if possible, get domain knowledge to intelligently impute these values.
3. Model building
Two ways to address missing values
There are several ways to address missing values, which is critical in EDA. The two primary methods are removing them and imputing other values in their place. Choosing the proper method depends on the business problem and the value the solution will add or take away from the dataset. Here, we will try both.
To compare the effect of different actions, first we’ll store the original number of values in a variable.
# Store the total number of values in a variable called `count_total`
count_total = df_companies.size
count_total12888
Now, we’ll remove all rows containing missing values.
# Drop the rows containing missing values,
# determine number of remaining values
count_dropna_rows = df_companies.dropna().size
count_dropna_rows12684
Now, let’s remove all columns containing missing values.
# Drop the columns containing missing values,
# determine number of remaining values
count_dropna_columns = df_companies.dropna(axis=1).size
count_dropna_columns10740
Next, print the percentage of values removed by each method and compare them.
# Print the percentage of values removed by dropping rows.
row_percent = ((count_total - count_dropna_rows) / count_total) * 100
print(f'Percentage removed, rows: {row_percent:.3f}')
# Print the percentage of values removed by dropping columns.
col_percent = ((count_total - count_dropna_columns) / count_total) * 100
print(f'Percentage removed, columns: {col_percent:.3f}')Percentage removed, rows: 1.583
Percentage removed, columns: 16.667
Which method was most effective?
The percentage removed was significantly higher for columns than it was for rows. Since both approaches result in a dataset with no missing values, the “most effective” method depends on how much data we have and what we want to do with it.
It might be best to use the way that leaves the most data intact—in this case, dropping rows. Or, if we don’t have many samples and don’t want to lose any, but we don’t need all our columns, then dropping columns might be best. With this data, it would probably be best to drop rows in the majority of cases.
Imputation
Now, let’s practice the second method: imputation.
We’ll use the fillna() method to fill each missing value with the next non-NaN value in its column.
Example:
df =
A B C
0 5 a NaN
1 10 NaN False
2 NaN c True
[IN]: df.fillna(method='backfill')
[OUT]:
A B C
0 5 a False
1 10 c False
2 NaN c True
Notice that if there is a NaN value in the last row, it will not backfill because there is no subsequent value in the column to refer to.
# 1. Fill missing values using the 'fillna()' method, back-filling
df_companies_backfill = df_companies.fillna(method='backfill')
# 2. Show the rows that previously had missing values
df_companies_backfill.iloc[df_missing_rows.index, :]| Company | Valuation | Date Joined | Industry | City | Country/Region | Continent | Year Founded | Funding | Select Investors | Year_Joined | valuation_num | |
| 12 | FTX | $32B | 7/20/21 | Fintech | Jacksonville | Bahamas | North America | 2018 | $2B | Sequoia Capital, Thoma Bravo, Softbank | 2021 | 32 |
| 170 | HyalRoute | $4B | 5/26/20 | Mobile & telecommunications | El Segundo | Singapore | Asia | 2015 | $263M | Kuang-Chi | 2020 | 4 |
| 242 | Moglix | $3B | 5/17/21 | E-commerce & direct-to-consumer | San Francisco | Singapore | Asia | 2015 | $471M | Jungle Ventures, Accel, Venture Highway | 2021 | 3 |
| 251 | Trax | $3B | 7/22/19 | Artificial intelligence | Amsterdam | Singapore | Asia | 2010 | $1B | Hopu Investment Management, Boyu Capital, DC T… | 2019 | 3 |
| 325 | Amber Group | $3B | 6/21/21 | Fintech | San Francisco | Hong Kong | Asia | 2015 | $328M | Tiger Global Management, Tiger Brokers, DCM Ve… | 2021 | 3 |
| 382 | Ninja Van | $2B | 9/27/21 | Supply chain, logistics, & delivery | San Francisco | Singapore | Asia | 2014 | $975M | B Capital Group, Monk’s Hill Ventures, Dynamic… | 2021 | 2 |
| 541 | Advance Intelligence Group | $2B | 9/23/21 | Artificial intelligence | Helsinki | Singapore | Asia | 2016 | $536M | Vision Plus Capital, GSR Ventures, ZhenFund | 2021 | 2 |
| 629 | LinkSure Network | $1B | 1/1/15 | Mobile & telecommunications | Shanghai | China | Asia | 2013 | $52M | Sequoia Capital India, The Times Group, GMO Ve… | 2015 | 1 |
| 811 | Carousell | $1B | 9/15/21 | E-commerce & direct-to-consumer | New York | Singapore | Asia | 2012 | $288M | 500 Global, Rakuten Ventures, Golden Gate Vent… | 2021 | 1 |
| 848 | Matrixport | $1B | 6/1/21 | Fintech | San Francisco | Singapore | Asia | 2019 | $100M | Dragonfly Captial, Qiming Venture Partners, DS… | 2021 | 1 |
| 880 | bolttech | $1B | 7/1/21 | Fintech | Englewood | Singapore | Asia | 2018 | $210M | Mundi Ventures, Doqling Capital Partners, Acti… | 2021 | 1 |
| 889 | Carro | $1B | 6/14/21 | E-commerce & direct-to-consumer | Lincoln | Singapore | Asia | 2015 | $595M | SingTel Innov8, Alpha JWC Ventures, Golden Gat… | 2021 | 1 |
| 893 | Cider | $1B | 9/2/21 | E-commerce & direct-to-consumer | Mexico City | Hong Kong | Asia | 2020 | $140M | Andreessen Horowitz, DST Global, IDG Capital | 2021 | 1 |
| 980 | NIUM | $1B | 7/13/21 | Fintech | Bengaluru | Singapore | Asia | 2014 | $285M | Vertex Ventures SE Asia, Global Founders Capit… | 2021 | 1 |
| 986 | ONE | $1B | 12/8/21 | Internet software & services | New York | Singapore | Asia | 2011 | $515M | Temasek, Guggenheim Investments, Qatar Investm… | 2021 | 1 |
| 994 | PatSnap | $1B | 3/16/21 | Internet software & services | London | Singapore | Asia | 2007 | $352M | Sequoia Capital China, Shunwei Capital Partner… | 2021 | 1 |
| 1061 | WeLab | $1B | 11/8/17 | Fintech | Beijing | Hong Kong | Asia | 2013 | $871M | Sequoia Capital China, ING, Alibaba Entreprene… | 2017 | 1 |
The values that were used to fill in for the missing values doesn’t make sense. The values seem to be added without consideration of the country those cities are located in.
Another option is to fill the values with a certain value, such as ‘Unknown’. However, doing so doesn’t add any value to the dataset and could make finding the missing values difficult in the future. Reviewing the missing values in this dataset determines that it is fine to leave the values as they are. This also avoids adding bias to the dataset.
4. Results and evaluation
Now that we’ve addressed our missing values, we can provide our investor with their requested data points.
Companies in the Hardware Industry
Remember our investor is interested in identifying unicorn companies in the Hardware industry in the following cities: Beijing, San Francisco, and London. They are also interested in companies in the Artificial intelligence industry in London.
We’ll write a selection statement that extracts the rows that meet these criteria. We’ll use the isin() Series method. This method is applied to a pandas series and, for each value in the series, checks whether it is a member of whatever is passed as its argument.
Example:
[IN]: my_series = pd.Series([0, 1, 2, 3])
my_series
[OUT]: 0 0
1 1
2 2
3 3
dtype: int64
[IN]: my_series.isin([1, 2])
[OUT]: 0 False
1 True
2 True
3 False
dtype: bool
# 1. Create a Boolean mask using conditional logic
cities = ['Beijing', 'San Francisco', 'London']
mask = (
(df_companies['Industry']=='Hardware') & (df_companies['City'].isin(cities))
) | (
(df_companies['Industry']=='Artificial intelligence') & (df_companies['City']=='London')
)
# 2. Apply the mask to the `df_companies` dataframe
# and assign the results to `df_invest`
df_invest = df_companies[mask]
df_invest| Company | Valuation | Date Joined | Industry | City | Country/Region | Continent | Year Founded | Funding | Select Investors | Year_Joined | valuation_num | |
| 36 | Bitmain | $12B | 7/6/18 | Hardware | Beijing | China | Asia | 2015 | $765M | Coatue Management, Sequoia Capital China, IDG … | 2018 | 12 |
| 43 | Global Switch | $11B | 12/22/16 | Hardware | London | United Kingdom | Europe | 1998 | $5B | Aviation Industry Corporation of China, Essenc… | 2016 | 11 |
| 147 | Chipone | $5B | 12/16/21 | Hardware | Beijing | China | Asia | 2008 | $1B | China Grand Prosperity Investment, Silk Road H… | 2021 | 5 |
| 845 | Density | $1B | 11/10/21 | Hardware | San Francisco | United States | North America | 2014 | $217M | Founders Fund, Upfront Ventures, 01 Advisors | 2021 | 1 |
| 873 | BenevolentAI | $1B | 6/2/15 | Artificial intelligence | London | United Kingdom | Europe | 2013 | $292M | Woodford Investment Management | 2015 | 1 |
| 923 | Geek+ | $1B | 11/21/18 | Hardware | Beijing | China | Asia | 2015 | $439M | Volcanics Ventures, Vertex Ventures China, War… | 2018 | 1 |
| 1040 | TERMINUS Technology | $1B | 10/25/18 | Hardware | Beijing | China | Asia | 2015 | $623M | China Everbright Limited, IDG Capital, iFLYTEK | 2018 | 1 |
| 1046 | Tractable | $1B | 6/16/21 | Artificial intelligence | London | United Kingdom | Europe | 2014 | $120M | Insight Partners, Ignition Partners, Georgian … | 2021 | 1 |
As seen above, eight companies meet the stated criteria.
List of countries by sum of valuation
For each country, we will sum the valuations of all companies in that country, then sort the results in descending order by summed valuation.
# Group the data by`Country/Region`
national_valuations = df_companies.groupby(['Country/Region'])['valuation_num'].sum()
.sort_values(ascending=False).reset_index()
# Print the top 15 values of the DataFrame.
national_valuations.head(15)| Country/Region | valuation_num | |
| 0 | United States | 1933 |
| 1 | China | 696 |
| 2 | India | 196 |
| 3 | United Kingdom | 195 |
| 4 | Germany | 72 |
| 5 | Sweden | 63 |
| 6 | Australia | 56 |
| 7 | France | 55 |
| 8 | Canada | 49 |
| 9 | South Korea | 41 |
| 10 | Israel | 39 |
| 11 | Brazil | 37 |
| 12 | Bahamas | 32 |
| 13 | Indonesia | 28 |
| 14 | Singapore | 21 |
The sorted data indicates that the four countries with highest total company valuations are the United States, China, India, and the United Kingdom. However, our investor specified that these countries should not be included in the list because they are outliers.
Filter out top 4 outlying countries
# Remove outlying countries
national_valuations_no_big4 = national_valuations.iloc[4:, :]
national_valuations_no_big4.head()| Country/Region | valuation_num | |
| 4 | Germany | 72 |
| 5 | Sweden | 63 |
| 6 | Australia | 56 |
| 7 | France | 55 |
| 8 | Canada | 49 |
Alternative approach
We can also use isin() to create a Boolean mask to filter out specific values of the Country/Region column. In this case, this process is longer and more complicated than simply using the iloc[] statement. However, there will be situations where this is the most direct approach.
# Use `isin()` to create a Boolean mask to accomplish the same task
mask = ~national_valuations['Country/Region'].isin(['United States', 'China', 'India', 'United Kingdom'])
national_valuations_no_big4 = national_valuations[mask]
national_valuations_no_big4.head()| Country/Region | valuation_num | |
| 4 | Germany | 72 |
| 5 | Sweden | 63 |
| 6 | Australia | 56 |
| 7 | France | 55 |
| 8 | Canada | 49 |
Notice that we wanted to filter out countries 1-4 and keep countries 5-46. Listing 42 countries wouldn’t be practical, so we inverted the statement with ~.
Create barplot for top 20 non-big-4 countries
Now, the data is ready to reveal the top 20 non-big-4 countries with the highest total company valuations.
# Create a barplot to compare the top 20 non-big-4 countries
# with highest company valuations
sns.barplot(data=national_valuations_no_big4.head(20),
y='Country/Region',
x='valuation_num')
plt.title('Top 20 non-big-4 countries by total company valuation')
plt.show()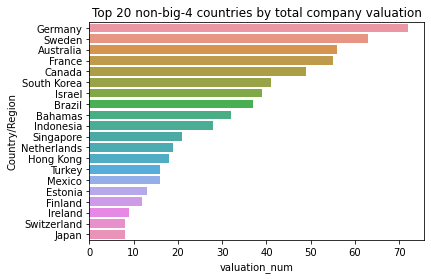
Plot maps
Our investor has also asked for a global valuation map of all countries except United States, China, India, and United Kingdom (a.k.a. “big-four countries”).
As we did before, we’ll create a scatter_geo() plot that depicts the total valuations of each non-big-four country on a world map, where each valuation is shown as a circle on the map, and the size of the circle is proportional to that country’s summed valuation.
# Plot the sum of valuations per country.
data = national_valuations_no_big4
px.scatter_geo(data,
locations='Country/Region',
size='valuation_num',
locationmode='country names',
color='Country/Region',
title='Total company valuations by country (non-big-four)')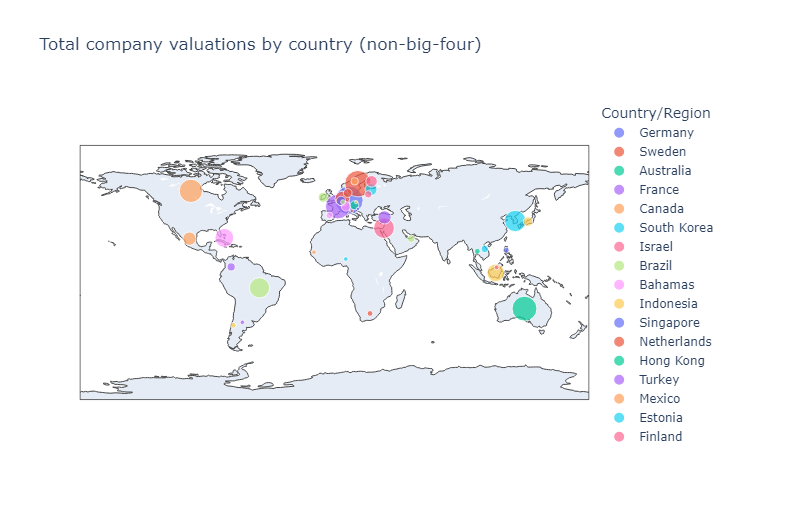
- Valuation sum per country is visualized by the size of circles around the map.
- Europe has a lot of unicorn companies in a concentrated area.
Conclusion
How would we present our findings from this lab to others?
- For the industry specific companies in certain locations, we could provide a short list of company names and locations.
- For the top 20 countries by sum of valuations, we could use the plot we created in this lab or share a list.
- For the top 20 countries sorted by sum of company valuations in each country, we would exclude United States, China, India, and United Kingdom.
- For the questions concerning the valuation map, in addition to our visuals, we would provide a short summary of the data points. This is because the investor did not request a further breakdown of this data.
Reference for this work: Bhat, M.A. Unicorn Companies