Identifying and Dealing with Outliers in Python
Objective
We will be examining lightning strike data collected by the National Oceanic and Atmospheric Association (NOAA) from 1987 through 2020. Because this would be many millions of rows to read into the notebook, Google’s team preprocessed the data so it contains just the year and the number of strikes.
We will examine the range of total lightning strike counts for each year and identify outliers. Then we will plot the yearly totals on a scatterplot.
Imports and loading the data
import matplotlib.pyplot as plt
import pandas as pd
import numpy as np
import seaborn as sns
# Read in data
df = pd.read_csv('eda_outliers_dataset1.csv')
df.head(10)| year | number_of_strikes | |
| 0 | 2020 | 15620068 |
| 1 | 2019 | 209166 |
| 2 | 2018 | 44600989 |
| 3 | 2017 | 35095195 |
| 4 | 2016 | 41582229 |
| 5 | 2015 | 37894191 |
| 6 | 2014 | 34919173 |
| 7 | 2013 | 27600898 |
| 8 | 2012 | 28807552 |
| 9 | 2011 | 31392058 |
Converting the numbers into strings and checking the means & medians
Let’s convert the number of strikes value to a more readable format on the graph.
def readable_numbers(x):
"""takes a large number and formats it into K,M to make it more readable"""
if x >= 1e6:
s = '{:1.1f}M'.format(x*1e-6)
else:
s = '{:1.0f}K'.format(x*1e-3)
return s
# Use the readable_numbers() function to create a new column
df['number_of_strikes_readable']=df['number_of_strikes'].apply(readable_numbers)
df.head(10)| year | number_of_strikes | number_of_strikes_readable | |
| 0 | 2020 | 15620068 | 15.6M |
| 1 | 2019 | 209166 | 209K |
| 2 | 2018 | 44600989 | 44.6M |
| 3 | 2017 | 35095195 | 35.1M |
| 4 | 2016 | 41582229 | 41.6M |
| 5 | 2015 | 37894191 | 37.9M |
| 6 | 2014 | 34919173 | 34.9M |
| 7 | 2013 | 27600898 | 27.6M |
| 8 | 2012 | 28807552 | 28.8M |
| 9 | 2011 | 31392058 | 31.4M |
print("Mean:" + readable_numbers(np.mean(df['number_of_strikes'])))
print("Median:" + readable_numbers(np.median(df['number_of_strikes'])))Mean:26.8M
Median:28.3M
Visualizing the results
One effective way to visualize outliers is a boxplot.
# Create boxplot
box = sns.boxplot(x=df['number_of_strikes'])
g = plt.gca()
box.set_xticklabels(np.array([readable_numbers(x) for x in g.get_xticks()]))
plt.xlabel('Number of strikes')
plt.title('Yearly number of lightning strikes')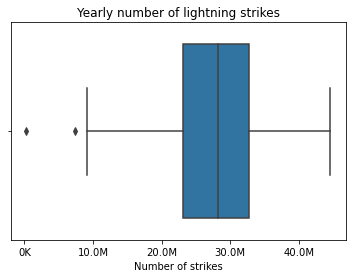
The points to the left of the left whisker are outliers. Any observations that are more than 1.5 IQR below Q1 or more than 1.5 IQR above Q3 are considered outliers.
One important point however is not assuming an outlier as erroneous unless there is an explanation or reason to do so.
Defining the IQR limits
Next piece of code will help us define our IQR, upper and lower limit.
# Calculate 25th percentile of annual strikes
percentile25 = df['number_of_strikes'].quantile(0.25)
# Calculate 75th percentile of annual strikes
percentile75 = df['number_of_strikes'].quantile(0.75)
# Calculate interquartile range
iqr = percentile75 - percentile25
# Calculate upper and lower thresholds for outliers
upper_limit = percentile75 + 1.5 * iqr
lower_limit = percentile25 - 1.5 * iqr
print('Lower limit is: '+ readable_numbers(lower_limit))Lower limit is: 8.6M
Now we can use a Boolean mask to select only the rows of the dataframe where the number of strikes is less than the lower limit we calculated above. These rows are the outliers on the low end.
# Isolate outliers on low end
df[df['number_of_strikes'] < lower_limit]| year | number_of_strikes | number_of_strikes_readable | |
| 1 | 2019 | 209166 | 209K |
| 33 | 1987 | 7378836 | 7.4M |
Visualization of the outliers
One great way of seeing these outliers in relation to the rest of the data points is a data visualization. For this plot, let’s do a scatter plot.
def addlabels(x,y):
for i in range(len(x)):
plt.text(x[i]-0.5, y[i]+500000, s=readable_numbers(y[i]))
colors = np.where(df['number_of_strikes'] < lower_limit, 'r', 'b')
fig, ax = plt.subplots(figsize=(16,8))
ax.scatter(df['year'], df['number_of_strikes'],c=colors)
ax.set_xlabel('Year')
ax.set_ylabel('Number of strikes')
ax.set_title('Number of lightning strikes by year')
addlabels(df['year'], df['number_of_strikes'])
for tick in ax.get_xticklabels():
tick.set_rotation(45)
plt.show()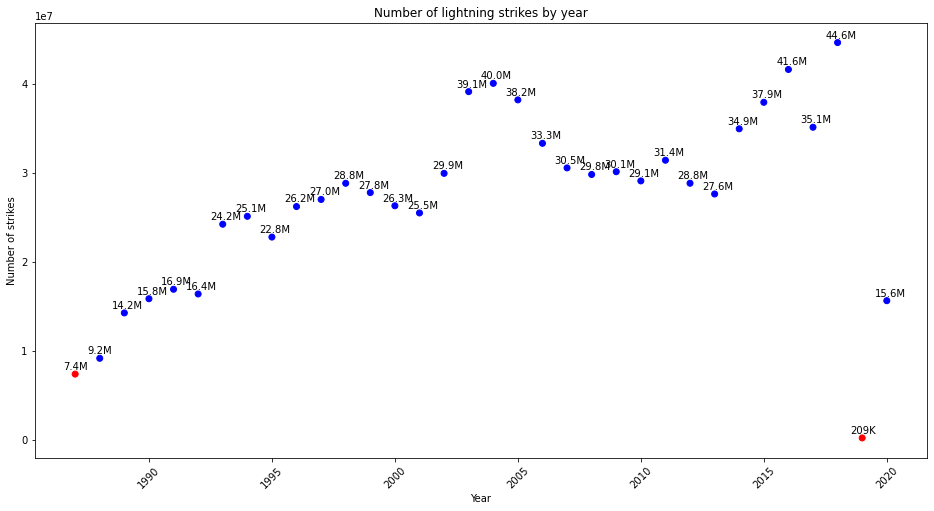
The ax refers to axis, which tells the notebook to plot the data on an x versus y data graphic.
Investigating the outliers 2019 and 1987
Let’s examine the two outlier years a bit more closely. In the section above, we used a preprocessed dataset that didn’t include a lot of the information that we’re accustomed to having in this data. In order to further investigate the outlier years, we’ll need more information, so we’re going to import data from these years specifically.
Data for 2019
df_2019 = pd.read_csv('eda_outliers_dataset2.csv')
df_2019.head()| date | number_of_strikes | center_point_geom | |
| 0 | 2019-12-01 | 1 | POINT(-79.7 35.3) |
| 1 | 2019-12-01 | 1 | POINT(-84.7 39.3) |
| 2 | 2019-12-01 | 1 | POINT(-83.4 38.9) |
| 3 | 2019-12-01 | 1 | POINT(-71.5 35.2) |
| 4 | 2019-12-01 | 1 | POINT(-87.8 41.6) |
First, lets convert the date column to datetime, as we did before with all the lightning datasets and then sort the data by month.
# Convert `date` column to datetime
df_2019['date']= pd.to_datetime(df_2019['date'])
# Create 2 new columns
df_2019['month'] = df_2019['date'].dt.month
df_2019['month_txt'] = df_2019['date'].dt.month_name().str.slice(stop=3)
# Group by `month` and `month_txt`, sum it, and sort. Assign result to new df
df_2019_by_month = df_2019.groupby(['month','month_txt']).sum().sort_values('month', ascending=True).head(12).reset_index()
df_2019_by_month| month | month_txt | number_of_strikes | |
| 0 | 12 | Dec | 209166 |
2019 appears to have data only for the month of December. The likelihood of there not being any lightning from January to November 2019 is ~0. This appears to be a case of missing data. We should probably exclude 2019 from the analysis (for most use cases).
Data for 1987
Now let’s inspect the data from the other outlier year, 1987.
# Read in 1987 data
df_1987 = pd.read_csv('eda_outliers_dataset3.csv')Now let’s do the same datetime conversions and groupings we did for the other datasets.
# Convert `date` column to datetime
df_1987['date'] = pd.to_datetime(df_1987['date'])
# Create 2 new columns
df_1987['month'] = df_1987['date'].dt.month
df_1987['month_txt'] = df_1987['date'].dt.month_name().str.slice(stop=3)
# Group by `month` and `month_txt`, sum it, and sort. Assign result to new df
df_1987_by_month = df_1987.groupby(['month','month_txt']).sum().sort_values('month', ascending=True).head(12).reset_index()
df_1987_by_month| month | month_txt | number_of_strikes | |
| 0 | 1 | Jan | 23044 |
| 1 | 2 | Feb | 61020 |
| 2 | 3 | Mar | 117877 |
| 3 | 4 | Apr | 157890 |
| 4 | 5 | May | 700910 |
| 5 | 6 | Jun | 1064166 |
| 6 | 7 | Jul | 2077619 |
| 7 | 8 | Aug | 2001899 |
| 8 | 9 | Sep | 869833 |
| 9 | 10 | Oct | 105627 |
| 10 | 11 | Nov | 155290 |
| 11 | 12 | Dec | 43661 |
This difference that 2019 does not have data for all months, and that 1987 does have data for all months, helps us to know how to handle these two outliers. For 2019, it would make sense to exclude it from our analysis. As for 1987, we recognize that it is indeed an outlier but it should not be excluded from our analysis because it does have lightning strike totals included for each month of the year.
Rechecking the Means and the Medians
Finally, let’s re-run the mean and median after removing the outliers.
# Create new df that removes outliers
df_without_outliers = df[df['number_of_strikes'] >= lower_limit]
# Recalculate mean and median values on data without outliers
print("Mean:" + readable_numbers(np.mean(df_without_outliers['number_of_strikes'])))
print("Median:" + readable_numbers(np.median(df_without_outliers['number_of_strikes'])))Mean:28.2M
Median:28.8M
Both the mean and the median changed, but the mean much more so. The outliers significantly affect the dataset’s mean, but do not significantly affect the median.