In this study, I’ll assume that I am a data professional working for the Department of Education of a large nation.
SciPy is an open source software we can use for solving mathematical, scientific, engineering, and technical problems. It allows us to manipulate and visualize data with a wide range of Python commands. SciPy stats is a module designed specifically for statistics.
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from scipy import stats
import statsmodels.api as smeducation_districtwise = pd.read_csv('education_districtwise.csv')
education_districtwise = education_districtwise.dropna()dropna() was used to remove missing values in our data.
Plotting a histogram
The first step in trying to model our data with a probability distribution is to plot a histogram. This will help us visualize the shape of our data and determine if it resembles the shape of a specific distribution.
education_districtwise['OVERALL_LI'].hist()<matplotlib.axes._subplots.AxesSubplot at 0x7f5f7f3e4590>
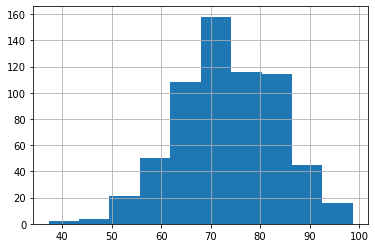
Normal Distribution
The histogram shows that the distribution of the literacy rate data is bell-shaped and symmetric about the mean. The mean literacy rate, which is around 73%, is located in the center of the plot.
The normal distribution is a continuous probability distribution that is bell-shaped and symmetrical on both sides of the mean. The shape of the histogram suggests that the normal distribution might be a good modeling option for the data.
Empirical rule
Since the normal distribution seems like a good fit for the district literacy rate data, we can expect the empirical rule to apply relatively well. In other words, we can expect that about 68 percent of literacy rates will fall within one standard deviation of the mean, 95 percent will fall within two standard deviations, and 99.7 percent will fall within three standard deviations.
Mean and the standard deviation
mean_overall_li = education_districtwise['OVERALL_LI'].mean()
mean_overall_li73.39518927444797
The mean district literacy rate is about 73.4%.
std_overall_li = education_districtwise['OVERALL_LI'].std()
std_overall_li 10.098460413782469
The standard deviation is about 10%.
Now, let’s compute the actual percentage of district literacy rates that fall within +/- 1 SD from the mean.
lower_limit = mean_overall_li - 1 * std_overall_li
upper_limit = mean_overall_li + 1 * std_overall_li
((education_districtwise['OVERALL_LI'] >= lower_limit) & (education_districtwise['OVERALL_LI'] <= upper_limit)).mean()0.6640378548895899
This is very close to the roughly 68 percent that the empirical rule suggests. Let’s use the same code structure to compute the actual percentage of district literacy rates that fall within +/- 2 SD and +/- 3 SD from the mean.
lower_limit = mean_overall_li - 2 * std_overall_li
upper_limit = mean_overall_li + 2 * std_overall_li
((education_districtwise['OVERALL_LI'] >= lower_limit) & (education_districtwise['OVERALL_LI'] <= upper_limit)).mean()0.9542586750788643
lower_limit = mean_overall_li - 3 * std_overall_li
upper_limit = mean_overall_li + 3 * std_overall_li
((education_districtwise['OVERALL_LI'] >= lower_limit) & (education_districtwise['OVERALL_LI'] <= upper_limit)).mean()0.9968454258675079
Our values of 66.4%, 95.4%, and 99.6% are very close to the values the empirical rule suggests: roughly 68%, 95%, and 99.7%.
At this point, it’s safe to say our data follows a normal distribution. Knowing that our data is normally distributed is useful for analysis because many statistical tests and machine learning models assume a normal distribution. Plus, when our data follows a normal distribution, we can use Z-scores to measure the relative position of our values and find outliers in our data.
Compute z-scores to find outliers
A z-score is a measure of how many standard deviations below or above the population mean a data point is. A z-score is useful because it tells us where a value lies in a distribution. Typically, data professionals consider observations with a z-score smaller than -3 or larger than +3 as outliers.
For example, if one tells us a literacy rate is 80 percent, this doesn’t give us much information about where the value lies in the distribution. However, if they also tell us the literacy rate has a Z-score of two, then we know that the value is two standard deviations above the mean.
We will compute the z-scores using the function scipy.stats.zscore().
education_districtwise['Z_SCORE'] = stats.zscore(education_districtwise['OVERALL_LI'])
education_districtwise| DISTNAME | STATNAME | BLOCKS | VILLAGES | CLUSTERS | TOTPOPULAT | OVERALL_LI | Z_SCORE | |
| 0 | DISTRICT32 | STATE1 | 13 | 391 | 104 | 875564.0 | 66.92 | -0.641712 |
| 1 | DISTRICT649 | STATE1 | 18 | 678 | 144 | 1015503.0 | 66.93 | -0.640721 |
| 2 | DISTRICT229 | STATE1 | 8 | 94 | 65 | 1269751.0 | 71.21 | -0.216559 |
| 3 | DISTRICT259 | STATE1 | 13 | 523 | 104 | 735753.0 | 57.98 | -1.527694 |
| 4 | DISTRICT486 | STATE1 | 8 | 359 | 64 | 570060.0 | 65.00 | -0.831990 |
| … | … | … | … | … | … | … | … | … |
| 675 | DISTRICT522 | STATE29 | 37 | 876 | 137 | 5296396.0 | 78.05 | 0.461307 |
| 676 | DISTRICT498 | STATE29 | 64 | 1458 | 230 | 4042191.0 | 56.06 | -1.717972 |
| 677 | DISTRICT343 | STATE29 | 59 | 1117 | 216 | 3483648.0 | 65.05 | -0.827035 |
| 678 | DISTRICT130 | STATE29 | 51 | 993 | 211 | 3522644.0 | 66.16 | -0.717030 |
| 679 | DISTRICT341 | STATE29 | 41 | 783 | 185 | 2798214.0 | 65.46 | -0.786403 |
634 rows × 8 columns
Now that we have computed z-scores for our dataset, we will write some code to identify outliers, or districts with z-scores that are more than +/- 3 SDs from the mean.
education_districtwise[(education_districtwise['Z_SCORE'] > 3) | (education_districtwise['Z_SCORE'] < -3)]| DISTNAME | STATNAME | BLOCKS | VILLAGES | CLUSTERS | TOTPOPULAT | OVERALL_LI | Z_SCORE | |
| 434 | DISTRICT461 | STATE31 | 4 | 360 | 53 | 532791.0 | 42.67 | -3.044964 |
| 494 | DISTRICT429 | STATE22 | 6 | 612 | 62 | 728677.0 | 37.22 | -3.585076 |
Using z-scores, we can identify two outlying districts that have unusually low literacy rates: DISTRICT461 and DISTRICT429.
Our analysis gives us important information to share. The government may want to provide more funding and resources to these two districts in the hopes of significantly improving literacy.
Probability distributions are useful for modeling our data and help us determine which statistical test to use for an analysis. In addition to the normal distribution, Python can help us work with a wide range of probability distributions too.