Analyzing one categorical variable
Let’s start with a simple data set.
| Drink | Type | Calories | Sugars (g) | Caffeine (mg) |
| Brewed coffee | Hot | 4 | 0 | 260 |
| Caffè latte | Hot | 100 | 14 | 75 |
| Caffè mocha | Hot | 170 | 27 | 95 |
| Cappuccino | Hot | 60 | 8 | 75 |
| Iced brewed coffee | Cold | 60 | 15 | 120 |
| Chai latte | Hot | 120 | 25 | 60 |
The individuals on this data set are drinks.
This data set contains 4 variables, 1 of which is categorical and 3 of which are quantitative.
Two-way tables
Sometimes (unlike the sample above) data belongs to more than one category. For example, cakes might have chocolate, coconut, both, or neither. We can use Venn diagrams and two-way tables to represent those data points.
Venn diagrams show sets and their overlaps. Two-way tables organize data in rows and columns and it shows how many data points fit in each category. Both methods help show relationships between categories.
The below Venn diagram and the two-way table show the same data.
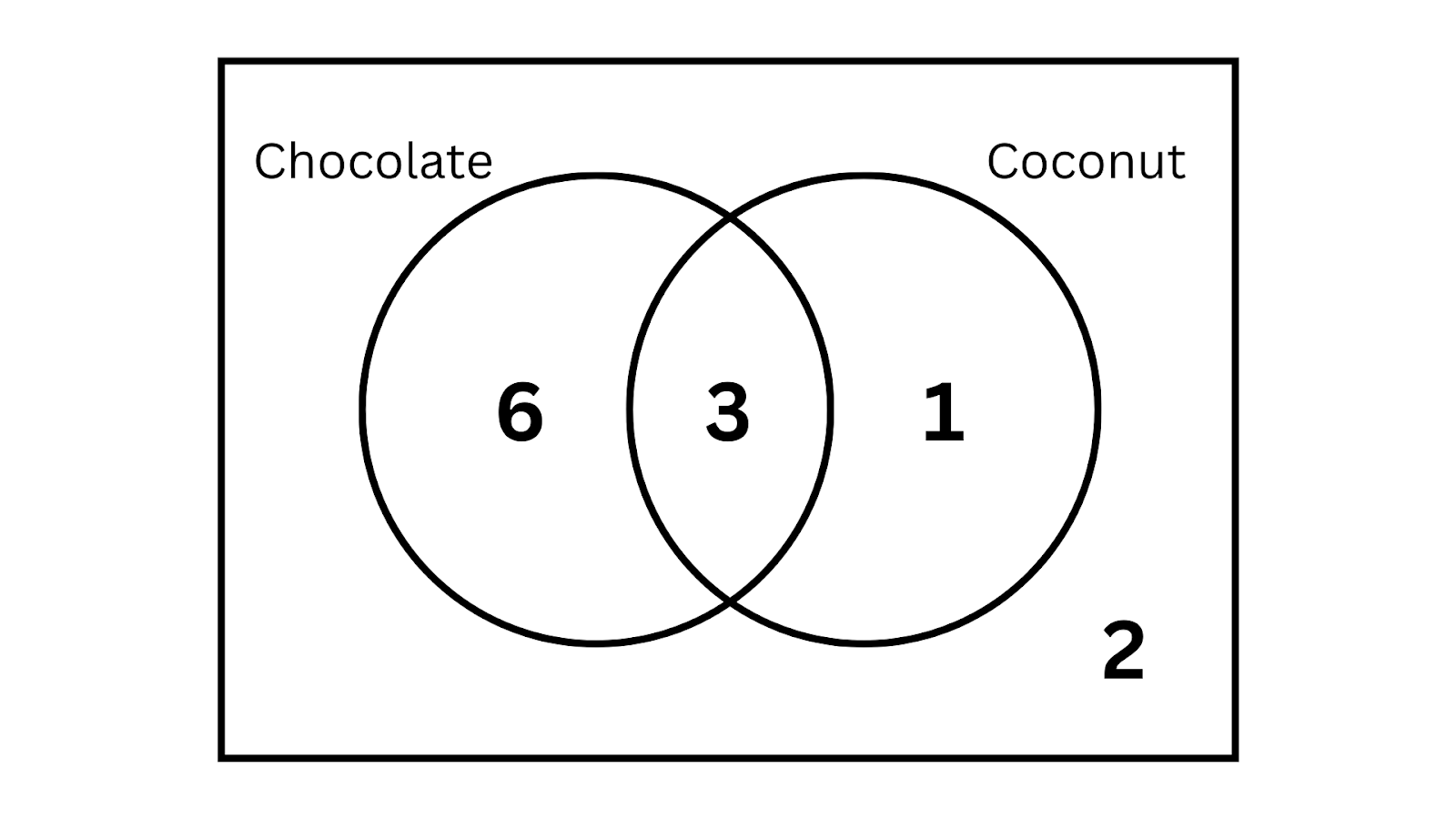
| coconut | no coconut | Σ | |
| chocolate | 3 | 6 | 9 |
| no chocolate | 1 | 2 | 3 |
| Σ | 4 | 8 | 12 |
Two-way relative frequency tables
Relative frequencies show how often something happens compared to the total number of times it could happen. This gives us a percentage or fraction rather than counts. They are good for seeing if there is an association between two variables.
Two-way relative frequency tables show what percent of data points fit in each category. We can use row relative frequencies or column relative frequencies, it just depends on the context of the problem.
| x | y | |
| A | 28 | 35 |
| B | 97 | 104 |
| x | y | |
| A | 0.22 | 0.25 |
| B | 0.78 | 0.75 |
| 1.00 | 1.00 |
Sometimes our percentages won’t add up to 100% even when we round properly. This is called round-off error.
Two-way relative frequency tables are useful when there are different sample sizes in a dataset.
Distribution in Two-way tables
We can talk about two types of distributions.
Marginal distribution focuses on one of the dimensions. We determine it by looking at the margin. It can be represented as counts or as percentages.
Conditional distribution is representing one variable given something true about the other variable. In other words, we look at the relationship between variables and understand how one variable impacts the distribution of another. The standard practice for conditional distribution is to think in terms of percentages.
| 0-20 min | 21-40 min | 41-60 min | >60 min | Total | |
| 80-100 % | 0 | 4 | 16 | 20 | 40 |
| 60-79 % | 0 | 20 | 30 | 10 | 60 |
| 40-59 % | 2 | 4 | 32 | 32 | 70 |
| 20-39 % | 10 | 2 | 8 | 0 | 20 |
| 0-19 % | 2 | 0 | 0 | 8 | 10 |
| Total | 14 | 30 | 86 | 70 | 200 |
To represent the marginal and conditional distributions, let’s add their respective percentages to the table as well.
| 0-20 min | 21-40 min | 41-60 min | >60 min | Total | |
| 80-100 % | 0 | 4 (13%) | 16 | 20 | 40 (20%) |
| 60-79 % | 0 | 20 (67%) | 30 | 10 | 60 (30%) |
| 40-59 % | 2 | 4 (13%) | 32 | 32 | 70 (35%) |
| 20-39 % | 10 | 2 (7%) | 8 | 0 | 20 (10%) |
| 0-19 % | 2 | 0 (0%) | 0 | 8 | 10 (5%) |
| Total | 14 (7%) | 30 (15%) | 86 (43%) | 70 (35%) | 200 |
Marginal distributions marked as bold. (represented as counts or percentages)
A conditional distribution marked as italic: Distribution of ‘the percentage correct answers’ given that students ‘study between 21-40 minutes’. (represented mostly as percentages)
Disclaimer: Like most of my posts, this content is intended solely for educational purposes and was created primarily for my personal reference. At times, I may rephrase original texts, and in some cases, I include materials such as graphs, equations, and datasets directly from their original sources.
I typically reference a variety of sources and update my posts whenever new or related information becomes available. For this particular post, the primary source was Khan Academy’s Statistics and Probability series.