Sample 1: Lightning Strikes
Following my notes on Python’s basic tools for data works, here I’ll do some basic EDA projects. Disclaimer: The one below is based on Google’s Advanced Data Analysis Program. My only intention, by repeating their structure, is to practice what I’ve learned and keep these notes as future reference. Their content can be reached via Coursera. A free version is also available without claiming the certificate.
Introduction
We will use pandas to examine 2018 lightning strike data collected by the National Oceanic and Atmospheric Administration (NOAA). Then, we will calculate the total number of strikes for each month and plot this information on a bar graph.
Imports
import pandas as pd
import numpy as np
import datetime as dt
import matplotlib.pyplot as plt
# Read in the 2018 lightning strike dataset.
df = pd.read_csv('eda_using_basic_data_functions_in_python_dataset1.csv')First Inspection
# Inspect the first 10 rows.
df.head(10)| date | number_of_strikes | center_point_geom | |
| 0 | 2018-01-03 | 194 | POINT(-75 27) |
| 1 | 2018-01-03 | 41 | POINT(-78.4 29) |
| 2 | 2018-01-03 | 33 | POINT(-73.9 27) |
| 3 | 2018-01-03 | 38 | POINT(-73.8 27) |
| 4 | 2018-01-03 | 92 | POINT(-79 28) |
| 5 | 2018-01-03 | 119 | POINT(-78 28) |
| 6 | 2018-01-03 | 35 | POINT(-79.3 28) |
| 7 | 2018-01-03 | 60 | POINT(-79.1 28) |
| 8 | 2018-01-03 | 41 | POINT(-78.7 28) |
| 9 | 2018-01-03 | 119 | POINT(-78.6 28) |
df.shape(3401012, 3)
# Get more information about the data, including data types of each column
df.info()<class 'pandas.core.frame.DataFrame'>
RangeIndex: 3401012 entries, 0 to 3401011
Data columns (total 3 columns):
# Column Dtype
--- ------ -----
0 date object
1 number_of_strikes int64
2 center_point_geom object
dtypes: int64(1), object(2)
memory usage: 77.8+ MB
Convert the date column to datetime
Converting string dates to datetime will enable us to work with them much more easily.
# Convert date column to datetime
df['date']= pd.to_datetime(df['date'])Calculate the days with the most strikes
We’ll try to get an idea of the highest data points by using a sum calculation. Using sum() performs a sum calculation on all other summable columns. In this case, we are summing all the lightning strikes that happened on each day.
Notice that the center_point_geom column is not included in the output below. That’s because, as a string object, this column is not summable.
# Calculate days with most lightning strikes.
df.groupby(['date']).sum().sort_values('number_of_strikes', ascending=False).head(10)| number_of_strikes | |
| date | |
| 2018-08-29 | 1070457 |
| 2018-08-17 | 969774 |
| 2018-08-28 | 917199 |
| 2018-08-27 | 824589 |
| 2018-08-30 | 802170 |
| 2018-08-19 | 786225 |
| 2018-08-18 | 741180 |
| 2018-08-16 | 734475 |
| 2018-08-31 | 723624 |
| 2018-08-15 | 673455 |
If we would use count instead of sum, it would return the number of occurrences of each date in the dataset, which is not the desired result.
Extract the month data
# Create a new `month` column
df['month'] = df['date'].dt.month
df.head()| date | number_of_strikes | center_point_geom | month | |
| 0 | 2018-01-03 | 194 | POINT(-75 27) | 1 |
| 1 | 2018-01-03 | 41 | POINT(-78.4 29) | 1 |
| 2 | 2018-01-03 | 33 | POINT(-73.9 27) | 1 |
| 3 | 2018-01-03 | 38 | POINT(-73.8 27) | 1 |
| 4 | 2018-01-03 | 92 | POINT(-79 28) | 1 |
Calculate the number of strikes per month
# Calculate total number of strikes per month
df.groupby(['month']).sum().sort_values('number_of_strikes', ascending=False).head(12)| number_of_strikes | |
| month | |
| 8 | 15525255 |
| 7 | 8320400 |
| 6 | 6445083 |
| 5 | 4166726 |
| 9 | 3018336 |
| 2 | 2071315 |
| 4 | 1524339 |
| 10 | 1093962 |
| 1 | 860045 |
| 3 | 854168 |
| 11 | 409263 |
| 12 | 312097 |
Convert the month number to text
To help read the data more easily, we can convert the month number to text using the datetime function dt.month_name() and add this as a new column in the dataframe. And str.slice will omit the text after the first three letters.
# Create a new `month_txt` column.
df['month_txt'] = df['date'].dt.month_name().str.slice(stop=3)| date | number_of_strikes | center_point_geom | month | month_txt | |
| 0 | 2018-01-03 | 194 | POINT(-75 27) | 1 | Jan |
| 1 | 2018-01-03 | 41 | POINT(-78.4 29) | 1 | Jan |
| 2 | 2018-01-03 | 33 | POINT(-73.9 27) | 1 | Jan |
| 3 | 2018-01-03 | 38 | POINT(-73.8 27) | 1 | Jan |
| 4 | 2018-01-03 | 92 | POINT(-79 28) | 1 | Jan |
Create a new dataframe
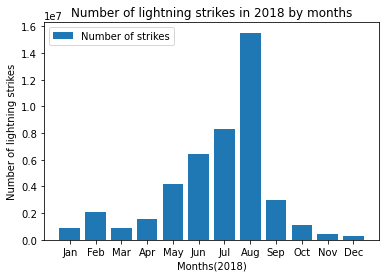
Our objective here is to plot the total number of strikes per month as a bar graph. We will also sort them by month for us to read easily.
# Create a new helper dataframe for plotting.
df_by_month = df.groupby(['month','month_txt']).sum().sort_values('month', ascending=True).head(12).reset_index()
df_by_month| month | month_txt | number_of_strikes | |
| 0 | 1 | Jan | 860045 |
| 1 | 2 | Feb | 2071315 |
| 2 | 3 | Mar | 854168 |
| 3 | 4 | Apr | 1524339 |
| 4 | 5 | May | 4166726 |
| 5 | 6 | Jun | 6445083 |
| 6 | 7 | Jul | 8320400 |
| 7 | 8 | Aug | 15525255 |
| 8 | 9 | Sep | 3018336 |
| 9 | 10 | Oct | 1093962 |
| 10 | 11 | Nov | 409263 |
| 11 | 12 | Dec | 312097 |
Make a bar chart
Pyplot’s plt.bar() function takes positional arguments of x and height, representing the data used for the x- and y- axes, respectively. Below, the x-axis will represent months, and the y-axis will represent strike count.
plt.bar(x=df_by_month['month_txt'],height= df_by_month['number_of_strikes'], label="Number of strikes")
plt.plot()
plt.xlabel("Months(2018)")
plt.ylabel("Number of lightning strikes")
plt.title("Number of lightning strikes in 2018 by months")
plt.legend()
plt.show()