Sample 2: Unicorn Companies
Following my notes on Python’s basic tools for data works, here I’ll do some basic EDA projects. Disclaimer: The one below is based on Google’s Advanced Data Analysis Program. My only intention, by repeating their structure, is to practice what I’ve learned and keep these notes as future reference. Their content can be reached via Coursera. A free version is also available without claiming the certificate.
The reference for the below work: Bhat, M.A. (2022, March). Unicorn Companies.
0. Introduction
We’ll imagine that we are a member of an analytics team that provides insights to an investing firm. To help them decide which companies to invest in next, the firm wants insights into unicorn companies, companies that are valued at over one billion dollars.
The data we will use for this task provides information on over 1,000 unicorn companies, including their industry, country, year founded, and select investors. We will use this information to gain insights into how and when companies reach this prestigious milestone and to make recommendations for next steps to the investing firm.
1. Imports
# Import libraries and packages
import pandas as pd
import matplotlib.pyplot as plt
import datetime as dt
# Load data from the csv file into a DataFrame and save in a variable
companies = pd.read_csv("Unicorn_Companies.csv")2. Data Exploration
# Display the first 10 rows of the data
companies.head(10)| Company | Valuation | Date Joined | Industry | City | Country/Region | Continent | Year Founded | Funding | Select Investors | |
| 0 | Bytedance | $180B | 4/7/17 | Artificial intelligence | Beijing | China | Asia | 2012 | $8B | Sequoia Capital China, SIG Asia Investments, S… |
| 1 | SpaceX | $100B | 12/1/12 | Other | Hawthorne | United States | North America | 2002 | $7B | Founders Fund, Draper Fisher Jurvetson, Rothen… |
| 2 | SHEIN | $100B | 7/3/18 | E-commerce & direct-to-consumer | Shenzhen | China | Asia | 2008 | $2B | Tiger Global Management, Sequoia Capital China… |
| 3 | Stripe | $95B | 1/23/14 | Fintech | San Francisco | United States | North America | 2010 | $2B | Khosla Ventures, LowercaseCapital, capitalG |
| 4 | Klarna | $46B | 12/12/11 | Fintech | Stockholm | Sweden | Europe | 2005 | $4B | Institutional Venture Partners, Sequoia Capita… |
| 5 | Canva | $40B | 1/8/18 | Internet software & services | Surry Hills | Australia | Oceania | 2012 | $572M | Sequoia Capital China, Blackbird Ventures, Mat… |
| 6 | Checkout.com | $40B | 5/2/19 | Fintech | London | United Kingdom | Europe | 2012 | $2B | Tiger Global Management, Insight Partners, DST… |
| 7 | Instacart | $39B | 12/30/14 | Supply chain, logistics, & delivery | San Francisco | United States | North America | 2012 | $3B | Khosla Ventures, Kleiner Perkins Caufield & By… |
| 8 | JUUL Labs | $38B | 12/20/17 | Consumer & retail | San Francisco | United States | North America | 2015 | $14B | Tiger Global Management |
| 9 | Databricks | $38B | 2/5/19 | Data management & analytics | San Francisco | United States | North America | 2013 | $3B | Andreessen Horowitz, New Enterprise Associates… |
# How large the dataset is
companies.size10740
# Shape of the dataset
companies.shape(1074, 10)
# Get basic information
companies.info()<class 'pandas.core.frame.DataFrame'>
RangeIndex: 1074 entries, 0 to 1073
Data columns (total 10 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 Company 1074 non-null object
1 Valuation 1074 non-null object
2 Date Joined 1074 non-null object
3 Industry 1074 non-null object
4 City 1058 non-null object
5 Country/Region 1074 non-null object
6 Continent 1074 non-null object
7 Year Founded 1074 non-null int64
8 Funding 1074 non-null object
9 Select Investors 1073 non-null object
dtypes: int64(1), object(9)
memory usage: 84.0+ KB
3. Statistical Tests
# Get descriptive statistics
companies.describe()| Year Founded | |
| count | 1074 |
| mean | 2012.895717 |
| std | 5.698573 |
| min | 1919 |
| 25% | 2011 |
| 50% | 2014 |
| 75% | 2016 |
| max | 2021 |
# Use pd.to_datetime() to convert Date Joined column to datetime
companies["Date Joined"] = pd.to_datetime(companies["Date Joined"])
# Use .dt.year to extract year component from Date Joined column
companies["Year Joined"] = companies["Date Joined"].dt.year
# Confirm the recent changes
companies.head()| Company | Valuation | Date Joined | Industry | City | Country/Region | Continent | Year Founded | Funding | Select Investors | Year Joined | |
| 0 | Bytedance | $180B | 2017-04-07 | Artificial intelligence | Beijing | China | Asia | 2012 | $8B | Sequoia Capital China, SIG Asia Investments, S… | 2017 |
| 1 | SpaceX | $100B | 2012-12-01 | Other | Hawthorne | United States | North America | 2002 | $7B | Founders Fund, Draper Fisher Jurvetson, Rothen… | 2012 |
| 2 | SHEIN | $100B | 2018-07-03 | E-commerce & direct-to-consumer | Shenzhen | China | Asia | 2008 | $2B | Tiger Global Management, Sequoia Capital China… | 2018 |
| 3 | Stripe | $95B | 2014-01-23 | Fintech | San Francisco | United States | North America | 2010 | $2B | Khosla Ventures, LowercaseCapital, capitalG | 2014 |
| 4 | Klarna | $46B | 2011-12-12 | Fintech | Stockholm | Sweden | Europe | 2005 | $4B | Institutional Venture Partners, Sequoia Capita… | 2011 |
4. Results and Evaluation
Take a sample of the data
It is not necessary to take a sample of the data in order to conduct the visualizations and EDA that follow. But we may encounter scenarios (in the future) where we will need to take a sample of the data due to time and resource limitations.
We’ll use sample() with the n parameter set to 50 to randomly sample 50 unicorn companies from the data. And we specify the random_state parameter to ensure reproducibility of our work.
# Sample the data
companies_sample = companies.sample(n = 50, random_state = 42)Visualize (the time it took companies to reach unicorn status)
We’ll visualize the longest time it took companies to reach unicorn status for each industry represented in the sample. But first we’ll need to prepare the data.
# Create new `years_till_unicorn` column
companies_sample["years_till_unicorn"] = companies_sample["Year Joined"] - companies_sample["Year Founded"]
# Group the data by `Industry`. For each industry,
# get the max value in the `years_till_unicorn` column.
grouped = (companies_sample[["Industry", "years_till_unicorn"]]
.groupby("Industry")
.max()
.sort_values(by="years_till_unicorn")
)
grouped| years_till_unicorn | |
| Industry | |
| Consumer & retail | 1 |
| Auto & transportation | 2 |
| Artificial intelligence | 5 |
| Data management & analytics | 8 |
| Mobile & telecommunications | 9 |
| Supply chain, logistics, & delivery | 12 |
| Internet software & services | 13 |
| Other | 15 |
| E-commerce & direct-to-consumer | 18 |
| Cybersecurity | 19 |
| Fintech | 21 |
| Health | 21 |
Now we can create a bar plot.
# Create bar plot with Industry column as the categories of the bars
# and the difference in years between Year Joined column
# and Year Founded column as the heights of the bars
plt.bar(grouped.index, grouped["years_till_unicorn"])
# Set title
plt.title("Bar plot of maximum years taken by company to become unicorn per industry (from sample)")
# Set x-axis label
plt.xlabel("Industry")
# Set y-axis label
plt.ylabel("Maximum number of years")
# Rotate labels on the x-axis as a way to avoid overlap in the positions of the text
plt.xticks(rotation=45, horizontalalignment='right')
# Display the plot
plt.show()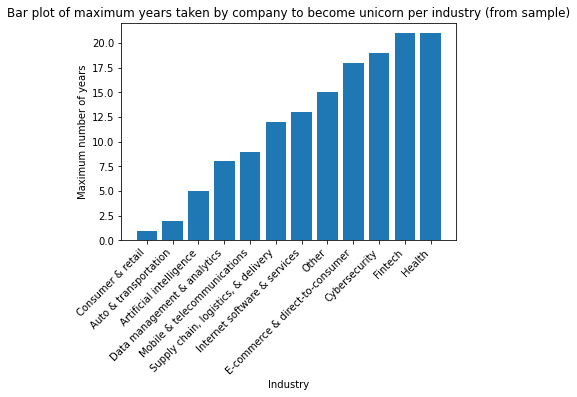
This bar plot shows that for this sample of unicorn companies, the largest value for maximum time taken to become a unicorn occurred in the Heath and Fintech industries, while the smallest value occurred in the Consumer & Retail industry.
My side note: These max digits may not be the representatives of their industries. They are rather some individual companies.
Visualize (the maximum unicorn company valuation per industry)
Visualize unicorn companies’ maximum valuation for each industry represented in the sample. But before plotting, we need to create a new column that represents the companies’ valuations as numbers (instead of strings, as they’re currently represented). Then, we’ll use this new column to plot our data.
# Create a column representing company valuation as numeric data
companies_sample['valuation_billions'] = companies_sample['Valuation']
# Remove the '$' from each value
companies_sample['valuation_billions'] = companies_sample['valuation_billions'].str.replace('$', '')
# Remove the 'B' from each value
companies_sample['valuation_billions'] = companies_sample['valuation_billions'].str.replace('B', '')
# Convert column to type int
companies_sample['valuation_billions'] = companies_sample['valuation_billions'].astype('int')
companies_sample.head()| Company | Valuation | Date Joined | Industry | City | Country/Region | Continent | Year Founded | Funding | Select Investors | Year Joined | years_till_unicorn | valuation_billions | |
| 542 | Aiven | $2B | 2021-10-18 | Internet software & services | Helsinki | Finland | Europe | 2016 | $210M | Institutional Venture Partners, Atomico, Early… | 2021 | 5 | 2 |
| 370 | Jusfoun Big Data | $2B | 2018-07-09 | Data management & analytics | Beijing | China | Asia | 2010 | $137M | Boxin Capital, DT Capital Partners, IDG Capital | 2018 | 8 | 2 |
| 307 | Innovaccer | $3B | 2021-02-19 | Health | San Francisco | United States | North America | 2014 | $379M | M12, WestBridge Capital, Lightspeed Venture Pa… | 2021 | 7 | 3 |
| 493 | Algolia | $2B | 2021-07-28 | Internet software & services | San Francisco | United States | North America | 2012 | $334M | Accel, Alven Capital, Storm Ventures | 2021 | 9 | 2 |
| 350 | SouChe Holdings | $3B | 2017-11-01 | E-commerce & direct-to-consumer | Hangzhou | China | Asia | 2012 | $1B | Morningside Ventures, Warburg Pincus, CreditEa… | 2017 | 5 | 3 |
My side note: Before doing the above modifications, we had to be sure that the Valuation column has all the same data format as in ‘$3B’.
Prepare data for modeling
grouped = (companies_sample[["Industry", "valuation_billions"]]
.groupby("Industry")
.max()
.sort_values(by="valuation_billions")
)
grouped| valuation_billions | |
| Industry | |
| Auto & transportation | 1 |
| Consumer & retail | 1 |
| Other | 2 |
| Supply chain, logistics, & delivery | 2 |
| Cybersecurity | 3 |
| Health | 3 |
| Data management & analytics | 4 |
| E-commerce & direct-to-consumer | 4 |
| Internet software & services | 5 |
| Mobile & telecommunications | 7 |
| Fintech | 10 |
| Artificial intelligence | 12 |
# Create bar plot with Industry column as the categories of the bars
# and new valuation column as the heights of the bars
plt.bar(grouped.index, grouped["valuation_billions"])
# Set title
plt.title("Bar plot of maximum unicorn company valuation per industry (from sample)")
# Set x-axis label
plt.xlabel("Industry")
# Set y-axis label
plt.ylabel("Maximum valuation in billions of dollars")
# Rotate labels on the x-axis as a way to avoid overlap in the positions of the text
plt.xticks(rotation=45, horizontalalignment='right')
# Display the plot
plt.show()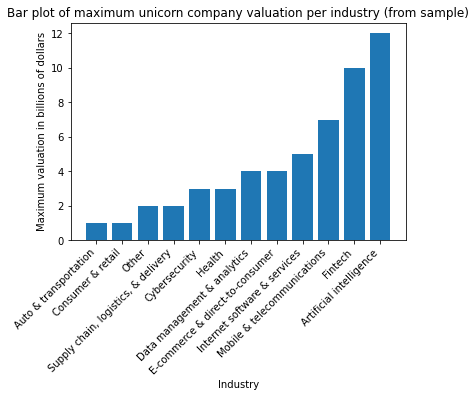
This bar plot shows that for this sample of unicorn companies, the highest maximum valuation occurred in the Artificial Intelligence industry, while the lowest maximum valuation occurred in the Auto & transportation, and Consumer & retail industries.
My side note: Again, these are just representatives of individual companies. We can’t reflect these digits to their entire industry.
What could be the next steps to consider?
- Identify the main industries that the investing firm is interested in investing in.
- Select a subset of this data that includes only companies in those industries.
- Analyze that subset more closely. Determine which companies have higher valuation but do not have as many investors currently. They may be good candidates to consider investing in.