Sample 3: Lightning Strikes
Following my notes on Python’s basic tools for data works, here I’ll do some basic EDA projects. Disclaimer: The one below is based on Google’s Advanced Data Analysis Program. My only intention, by repeating their structure, is to practice what I’ve learned and keep these notes as future reference. Their content can be reached via Coursera. A free version is also available without claiming the certificate.
Introduction
As we did with sample 1, we will work with 2016–2018 lightning strike data from the National Oceanic and Atmospheric Association (NOAA). But this time we will calculate weekly sums of lightning strikes and plot them on a bar graph. Then, we will calculate quarterly lightning strike totals and plot them on bar graphs.
Imports
import pandas as pd
import datetime as dt
import matplotlib.pyplot as plt
Import seaborn as sns
# Read in the data.
df = pd.read_csv('eda_manipulate_date_strings_with_python.csv')
df.head()| date | number_of_strikes | center_point_geom | |
| 0 | 2016-08-05 | 16 | POINT(-101.5 24.7) |
| 1 | 2016-08-05 | 16 | POINT(-85 34.3) |
| 2 | 2016-08-05 | 16 | POINT(-89 41.4) |
| 3 | 2016-08-05 | 16 | POINT(-89.8 30.7) |
| 4 | 2016-08-05 | 16 | POINT(-86.2 37.9) |
Create new time columns with string format time
When a date column data type is a string object, it limits what we can do with it. That’s why we’ll convert the column to datetime (once again).
# Convert the 'date' column to datetime.
df['date'] = pd.to_datetime(df['date'])Now we can create new columns to represent week, month, quarter, and year by using datetime.strftime() method. We will use strftime format codes: %Y for year, %V for week number, %q for quarter.
# Create four new columns.
df['week'] = df['date'].dt.strftime('%Y-W%V')
df['month'] = df['date'].dt.strftime('%Y-%m')
df['quarter'] = df['date'].dt.to_period('Q').dt.strftime('%Y-Q%q')
df['year'] = df['date'].dt.strftime('%Y')
df.head(10)| date | number_of_strikes | center_point_geom | week | month | quarter | year | |
| 0 | 2016-08-05 | 16 | POINT(-101.5 24.7) | 2016-W31 | 2016-08 | 2016-Q3 | 2016 |
| 1 | 2016-08-05 | 16 | POINT(-85 34.3) | 2016-W31 | 2016-08 | 2016-Q3 | 2016 |
| 2 | 2016-08-05 | 16 | POINT(-89 41.4) | 2016-W31 | 2016-08 | 2016-Q3 | 2016 |
| 3 | 2016-08-05 | 16 | POINT(-89.8 30.7) | 2016-W31 | 2016-08 | 2016-Q3 | 2016 |
| 4 | 2016-08-05 | 16 | POINT(-86.2 37.9) | 2016-W31 | 2016-08 | 2016-Q3 | 2016 |
| 5 | 2016-08-05 | 16 | POINT(-97.8 38.9) | 2016-W31 | 2016-08 | 2016-Q3 | 2016 |
| 6 | 2016-08-05 | 16 | POINT(-81.9 36) | 2016-W31 | 2016-08 | 2016-Q3 | 2016 |
| 7 | 2016-08-05 | 16 | POINT(-90.9 36.7) | 2016-W31 | 2016-08 | 2016-Q3 | 2016 |
| 8 | 2016-08-05 | 16 | POINT(-106.6 26.1) | 2016-W31 | 2016-08 | 2016-Q3 | 2016 |
| 9 | 2016-08-05 | 16 | POINT(-108 31.6) | 2016-W31 | 2016-08 | 2016-Q3 | 2016 |
Plot the number of weekly lightning strikes in 2018
First we’ll start by filtering the dataset.
# Create a new dataframe view of just 2018 data, summed by week.
df_by_week_2018 = df[df['year'] == '2018'].groupby(['week']).sum().reset_index()
df_by_week_2018.head()| week | number_of_strikes | |
| 0 | 2018-W01 | 34843 |
| 1 | 2018-W02 | 353425 |
| 2 | 2018-W03 | 37132 |
| 3 | 2018-W04 | 412772 |
| 4 | 2018-W05 | 34972 |
Note: In pandas v.2.X+ we must set ‘numeric_only=True’ in the sum() function or else it will throw an error.
Now we have the table to plot.
# Plot a bar graph of weekly strike totals in 2018.
plt.bar(x = df_by_week_2018['week'], height = df_by_week_2018['number_of_strikes'])
plt.plot()
plt.xlabel("Week number")
plt.ylabel("Number of lightning strikes")
plt.title("Number of lightning strikes per week (2018)")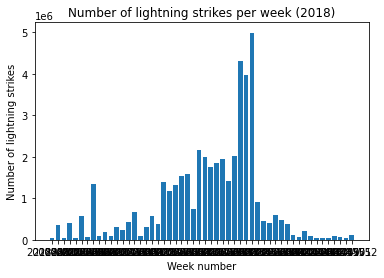
Because the x-axis labels are too crowded, we need to adjust the graph.
plt.figure(figsize = (20, 5)) # Increase output size.
plt.bar(x = df_by_week_2018['week'], height = df_by_week_2018['number_of_strikes'])
plt.plot()
plt.xlabel("Week number")
plt.ylabel("Number of lightning strikes")
plt.title("Number of lightning strikes per week (2018)")
plt.xticks(rotation = 45, fontsize = 8) # Rotate x-axis labels and decrease font size.
plt.show()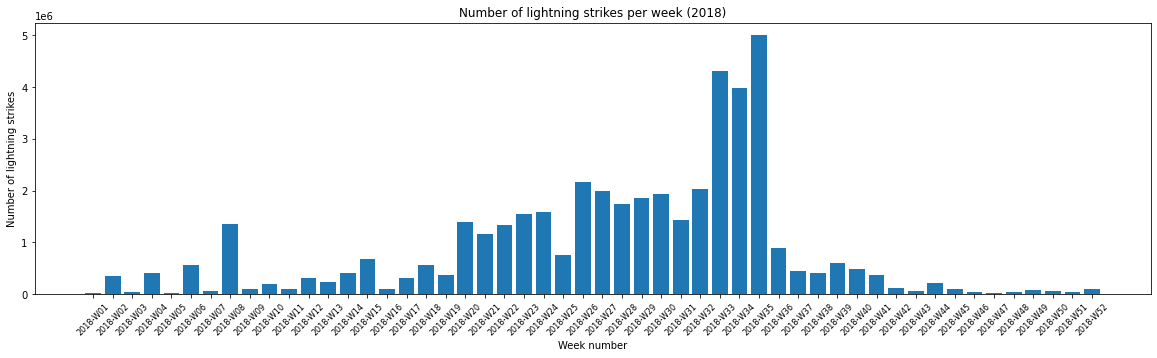
Plot the number of quarterly lightning strikes from 2016–2018
Now let’s work on the full date range of available data and use quarters as our smaller chunks to investigate.
# Group 2016-2018 data by quarter and sum.
df_by_quarter = df.groupby(['quarter']).sum().reset_index()
# Format as text, in millions.
df_by_quarter['number_of_strikes_formatted'] = df_by_quarter['number_of_strikes'].div(1000000).round(1).astype(str) + 'M'
df_by_quarter.head()| quarter | number_of_strikes | number_of_strikes_formatted | |
| 0 | 2016-Q1 | 2683798 | 2.7M |
| 1 | 2016-Q2 | 15084857 | 15.1M |
| 2 | 2016-Q3 | 21843820 | 21.8M |
| 3 | 2016-Q4 | 1969754 | 2.0M |
| 4 | 2017-Q1 | 2444279 | 2.4M |
Above, we created a new formatted column, divided its results by one million, rounded to one digit after the decimal point, and lastly converted it to a string to add “M” to the end, representing millions. This was for us to easily read the table and also use on the bar graph below as labels.
Add labels
To be able to use these new formatted column values as labels, first we need to define our own functions. The function uses plt.text(), which is a pyplot function whose positional arguments are x, y, and s.
x represents the x-axis coordinates, y represents the y-axis coordinates, and s represents the text that we want to appear at these coordinates. For more information: pyplot documentation.
def addlabels(x, y, labels):
'''
Iterates over data and plots text labels above each bar of bar graph.
'''
for i in range(len(x)):
plt.text(i, y[i], labels[i], ha = 'center', va = 'bottom')Now we can plot the bar.
plt.figure(figsize = (15, 5))
plt.bar(x = df_by_quarter['quarter'], height = df_by_quarter['number_of_strikes'])
addlabels(df_by_quarter['quarter'], df_by_quarter['number_of_strikes'], df_by_quarter['number_of_strikes_formatted'])
plt.plot()
plt.xlabel('Quarter')
plt.ylabel('Number of lightning strikes')
plt.title('Number of lightning strikes per quarter (2016-2018)')
plt.show()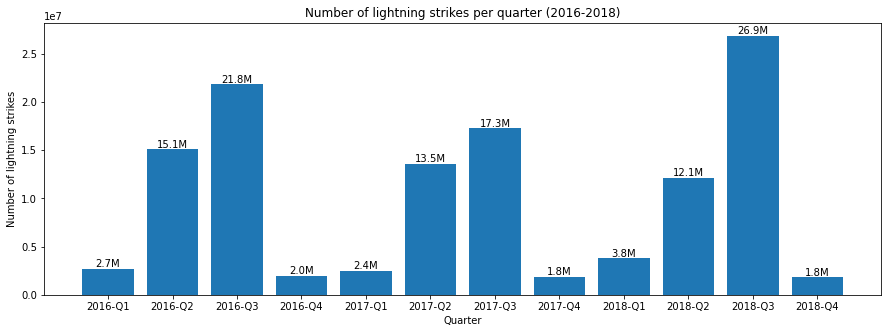
Create a grouped bar chart
In most cases there will be some other ways to show the same data differently. For instance, now we can create a grouped bar chart to better compare year-over-year changes each quarter.
But again, before plotting we need to prepare our data for it. We’ll create two new columns that break out the quarter and year from the quarter column. We will use the quarter column and take the last two characters to get quarter_number, and take the first four characters to get the year.
# Create two new columns.
df_by_quarter['quarter_number'] = df_by_quarter['quarter'].str[-2:]
df_by_quarter['year'] = df_by_quarter['quarter'].str[:4]
df_by_quarter.head()| quarter | number_of_strikes | number_of_strikes_formatted | quarter_number | year | |
| 0 | 2016-Q1 | 2683798 | 2.7M | Q1 | 2016 |
| 1 | 2016-Q2 | 15084857 | 15.1M | Q2 | 2016 |
| 2 | 2016-Q3 | 21843820 | 21.8M | Q3 | 2016 |
| 3 | 2016-Q4 | 1969754 | 2.0M | Q4 | 2016 |
| 4 | 2017-Q1 | 2444279 | 2.4M | Q1 | 2017 |
My Side Note: Before coming to this point (by this I mean, before creating df_by_quarter dataframe), I’d probably retrieve months, weeks, and quarters (or whatever I be in need of) from the date column by simply using dt.year, dt.quarter, etc.
Now we can create our bar chart with seaborn.
plt.figure(figsize = (15, 5))
p = sns.barplot(
data = df_by_quarter,
x = 'quarter_number',
y = 'number_of_strikes',
hue = 'year')
for b in p.patches:
p.annotate(str(round(b.get_height()/1000000, 1))+'M',
(b.get_x() + b.get_width() / 2., b.get_height() + 1.2e6),
ha = 'center', va = 'bottom',
xytext = (0, -12),
textcoords = 'offset points')
plt.xlabel("Quarter")
plt.ylabel("Number of lightning strikes")
plt.title("Number of lightning strikes per quarter (2016-2018)")
plt.show()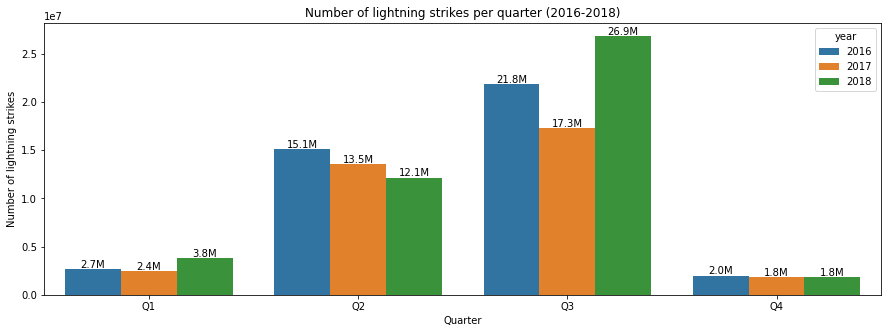
In the code above, Google uses a different method (much complicated one) to add labels on each bar. I need more time to grasp those.