Sample 4: Lightning Strikes
Following my notes on Python’s basic tools for data works, here I’ll do some basic EDA projects. Disclaimer: The one below is based on Google’s Advanced Data Analysis Program. My only intention, by repeating their structure, is to practice what I’ve learned and keep these notes as future reference. Their content can be reached via Coursera. A free version is also available without claiming the certificate.
Introduction
As we did with sample 1 and sample 3, we will again work on lightning strike data collected by the National Oceanic and Atmospheric Association (NOAA) for the year of 2018. We will use our structuring tools to learn more about whether lightning strikes are more prevalent on some days than others.
We will follow these steps:
- Find the locations with the greatest number of strikes within a single day
- Examine the locations that had the greatest number of days with at least one lightning strike
- Determine whether certain days of the week had more lightning strikes than others
- Add data from 2016 and 2017 and, for each month, calculate the percentage of total lightning strikes for that year that occurred in that month
- Plot this data on a bar graph
Imports
import pandas as pd
import numpy as np
import seaborn as sns
import datetime
from matplotlib import pyplot as plt
# Read in the 2018 data.
df = pd.read_csv('eda_structuring_with_python_dataset1.csv')
df.head()| date | number_of_strikes | center_point_geom | |
| 0 | 2018-01-03 | 194 | POINT(-75 27) |
| 1 | 2018-01-03 | 41 | POINT(-78.4 29) |
| 2 | 2018-01-03 | 33 | POINT(-73.9 27) |
| 3 | 2018-01-03 | 38 | POINT(-73.8 27) |
| 4 | 2018-01-03 | 92 | POINT(-79 28) |
As we did earlier with the same dataset, let’s first convert the date column to datetime.
# Convert the 'date' column to datetime.
df['date'] = pd.to_datetime(df['date']) Let’s check the shape of the dataframe.
df.shape(3401012, 3)
Now checking the duplicates.
df.drop_duplicates().shape(3401012, 3)
With the code above the notebook returns the number of rows, and columns remaining after duplicates are removed. Since they are the same, it means that we don’t have any duplicates. (I usually don’t drop duplicated without understanding what are they first.)
Locations with most strikes in a single day
# Sort by number of strikes in descending order.
df.sort_values(by='number_of_strikes', ascending=False).head(10)| date | number_of_strikes | center_point_geom | |
| 302758 | 2018-08-20 | 2211 | POINT(-92.5 35.5) |
| 278383 | 2018-08-16 | 2142 | POINT(-96.1 36.1) |
| 280830 | 2018-08-17 | 2061 | POINT(-90.2 36.1) |
| 280453 | 2018-08-17 | 2031 | POINT(-89.9 35.9) |
| 278382 | 2018-08-16 | 1902 | POINT(-96.2 36.1) |
| 11517 | 2018-02-10 | 1899 | POINT(-95.5 28.1) |
| 277506 | 2018-08-16 | 1878 | POINT(-89.7 31.5) |
| 24906 | 2018-02-25 | 1833 | POINT(-98.7 28.9) |
| 284320 | 2018-08-17 | 1767 | POINT(-90.1 36) |
| 24825 | 2018-02-25 | 1741 | POINT(-98 29) |
Locations with most days with at least one lightning strike
# Identify the locations that appear most in the dataset.
df.center_point_geom.value_counts()POINT(-81.5 22.5) 108
POINT(-84.1 22.4) 108
POINT(-82.5 22.9) 107
POINT(-82.7 22.9) 107
POINT(-82.5 22.8) 106
...
POINT(-119.3 35.1) 1
POINT(-119.3 35) 1
POINT(-119.6 35.6) 1
POINT(-119.4 35.6) 1
POINT(-58.5 45.3) 1
Name: center_point_geom, Length: 170855, dtype: int64
Now let’s examine whether there is an even distribution of values, or whether 108 strikes is an unusually high number of days with lightning strikes.
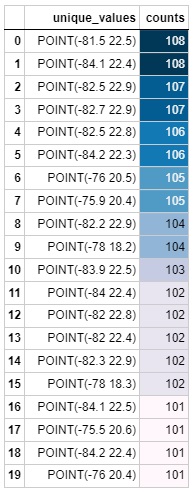
# Identify the top 20 locations with most days of lightning.
df.center_point_geom.value_counts()[:20].rename_axis('unique_values').reset_index(name='counts').style.background_gradient()| unique_values | counts | |
| 0 | POINT(-81.5 22.5) | 108 |
| 1 | POINT(-84.1 22.4) | 108 |
| 2 | POINT(-82.5 22.9) | 107 |
| 3 | POINT(-82.7 22.9) | 107 |
| 4 | POINT(-82.5 22.8) | 106 |
| 5 | POINT(-84.2 22.3) | 106 |
| 6 | POINT(-76 20.5) | 105 |
| 7 | POINT(-75.9 20.4) | 105 |
| 8 | POINT(-82.2 22.9) | 104 |
| 9 | POINT(-78 18.2) | 104 |
| 10 | POINT(-83.9 22.5) | 103 |
| 11 | POINT(-84 22.4) | 102 |
| 12 | POINT(-82 22.8) | 102 |
| 13 | POINT(-82 22.4) | 102 |
| 14 | POINT(-82.3 22.9) | 102 |
| 15 | POINT(-78 18.3) | 102 |
| 16 | POINT(-84.1 22.5) | 101 |
| 17 | POINT(-75.5 20.6) | 101 |
| 18 | POINT(-84.2 22.4) | 101 |
| 19 | POINT(-76 20.4) | 101 |
Lightning strikes by day of week
Let’s check whether any particular day of the week had fewer or more lightning strikes than others. First we’ll use two methods below.
(More about dt.isocalendar(): pandas.Series.dt.isocalendar documentation.
More about dt.day_name(): pandas.Series.dt.day_name documentation.)
# Create two new columns.
df['week'] = df.date.dt.isocalendar().week
df['weekday'] = df.date.dt.day_name()
df.head()| date | number_of_strikes | center_point_geom | week | weekday | |
| 0 | 2018-01-03 | 194 | POINT(-75 27) | 1 | Wednesday |
| 1 | 2018-01-03 | 41 | POINT(-78.4 29) | 1 | Wednesday |
| 2 | 2018-01-03 | 33 | POINT(-73.9 27) | 1 | Wednesday |
| 3 | 2018-01-03 | 38 | POINT(-73.8 27) | 1 | Wednesday |
| 4 | 2018-01-03 | 92 | POINT(-79 28) | 1 | Wednesday |
Now, we can calculate the mean number of lightning strikes for each weekday of the year.
# Calculate the mean count of lightning strikes for each weekday.
df[['weekday','number_of_strikes']].groupby(['weekday']).mean()| number_of_strikes | |
| weekday | |
| Friday | 13.349972 |
| Monday | 13.152804 |
| Saturday | 12.732694 |
| Sunday | 12.324717 |
| Thursday | 13.240594 |
| Tuesday | 13.813599 |
| Wednesday | 13.224568 |
It seems that Saturday and Sunday have fewer lightning strikes on average than the other five weekdays. To understand better what this data is telling us, let’s plot a box plot chart.
A boxplot is a data visualization that depicts the locality, spread, and skew of groups of values within quartiles.
# Define order of days for the plot.
weekday_order = ['Monday','Tuesday', 'Wednesday', 'Thursday','Friday','Saturday','Sunday']
# Create boxplots of strike counts for each day of week.
g = sns.boxplot(data=df,
x='weekday',
y='number_of_strikes',
order=weekday_order,
showfliers=False #outliers are left off of the box plot
)
g.set_title('Lightning distribution per weekday (2018)')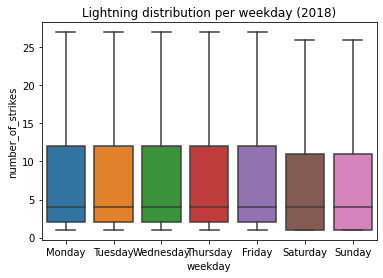
Notice that the median remains the same on all of the days of the week. As for Saturday and Sunday, however, the distributions are both lower than they are during the rest of the week. We also know that the mean numbers of strikes that occurred on Saturday and Sunday were lower than on the other weekdays. Why might this be?
Perhaps the aerosol particles emitted by factories and vehicles increase the likelihood of lightning strikes. In the U.S., Saturday and Sunday are days that many people don’t work, so there may be fewer factories operating and fewer cars on the road. This is only speculation, but it’s one possible path for further exploration. While we don’t know for sure, we have clear data suggesting the total quantity of weekend lightning strikes is lower than weekdays.
Monthly lightning strikes 2016–2018
To examine further let’s check our data across multiple years. We will calculate the percentage of total lightning strikes for each year that occurred in a given month. We will then plot this data on a bar graph.
# Import 2016–2017 data
df_2 = pd.read_csv('eda_structuring_with_python_dataset2.csv')
df_2.head()| date | number_of_strikes | center_point_geom | |
| 0 | 2016-01-04 | 55 | POINT(-83.2 21.1) |
| 1 | 2016-01-04 | 33 | POINT(-83.1 21.1) |
| 2 | 2016-01-05 | 46 | POINT(-77.5 22.1) |
| 3 | 2016-01-05 | 28 | POINT(-76.8 22.3) |
| 4 | 2016-01-05 | 28 | POINT(-77 22.1) |
As we did earlier, we will convert the date column to datetime.
# Convert `date` column to datetime.
df_2['date'] = pd.to_datetime(df_2['date'])To merge three years of data together, we need to make sure each dataset is formatted the same. The new datasets do not have the extra columns week and weekday that we created earlier. There’s an easy way to merge the three years of data and remove the extra columns at the same time.
# Create a new dataframe combining 2016–2017 data with 2018 data.
union_df = pd.concat([df.drop(['weekday','week'],axis=1), df_2], ignore_index=True)
union_df.head()| date | number_of_strikes | center_point_geom | |
| 0 | 2018-01-03 | 194 | POINT(-75 27) |
| 1 | 2018-01-03 | 41 | POINT(-78.4 29) |
| 2 | 2018-01-03 | 33 | POINT(-73.9 27) |
| 3 | 2018-01-03 | 38 | POINT(-73.8 27) |
| 4 | 2018-01-03 | 92 | POINT(-79 28) |
Note that the above code doesn’t permanently modify df. The columns drop only for this operation.
Again as we did earlier, we will create three new columns that isolate the year, month number, and month name.
# Add 3 new columns.
union_df['year'] = union_df.date.dt.year
union_df['month'] = union_df.date.dt.month
union_df['month_txt'] = union_df.date.dt.month_name()
union_df.head()| date | number_of_strikes | center_point_geom | year | month | month_txt | |
| 0 | 2018-01-03 | 194 | POINT(-75 27) | 2018 | 1 | January |
| 1 | 2018-01-03 | 41 | POINT(-78.4 29) | 2018 | 1 | January |
| 2 | 2018-01-03 | 33 | POINT(-73.9 27) | 2018 | 1 | January |
| 3 | 2018-01-03 | 38 | POINT(-73.8 27) | 2018 | 1 | January |
| 4 | 2018-01-03 | 92 | POINT(-79 28) | 2018 | 1 | January |
Let’s check the overall lightning strike count for each year.
# Calculate total number of strikes per year
union_df[['year','number_of_strikes']].groupby(['year']).sum()| number_of_strikes | |
| year | |
| 2016 | 41582229 |
| 2017 | 35095195 |
| 2018 | 44600989 |
Because the totals are different, it might be interesting as part of our analysis to see lightning strike percentages by month of each year.
# Calculate total lightning strikes for each month of each year.
lightning_by_month = union_df.groupby(['month_txt','year']).agg(
number_of_strikes = pd.NamedAgg(column='number_of_strikes',aggfunc=sum)
).reset_index()
lightning_by_month.head()| month_txt | year | number_of_strikes | |
| 0 | April | 2016 | 2636427 |
| 1 | April | 2017 | 3819075 |
| 2 | April | 2018 | 1524339 |
| 3 | August | 2016 | 7250442 |
| 4 | August | 2017 | 6021702 |
Similarly we can use the agg() function to calculate the same yearly totals we found before.
# Calculate total lightning strikes for each year.
lightning_by_year = union_df.groupby(['year']).agg(
year_strikes = pd.NamedAgg(column='number_of_strikes',aggfunc=sum)
).reset_index()
lightning_by_year.head()| year | year_strikes | |
| 0 | 2016 | 41582229 |
| 1 | 2017 | 35095195 |
| 2 | 2018 | 44600989 |
We created those two data frames, lightning by month and lightning by year in order to derive our percentages of lightning strikes by month and year.
# Combine 'lightning_by_month' and 'lightning_by_year' dataframes into single dataframe.
percentage_lightning = lightning_by_month.merge(lightning_by_year,on='year')
percentage_lightning.head()| month_txt | year | number_of_strikes | year_strikes | |
| 0 | April | 2016 | 2636427 | 41582229 |
| 1 | August | 2016 | 7250442 | 41582229 |
| 2 | December | 2016 | 316450 | 41582229 |
| 3 | February | 2016 | 312676 | 41582229 |
| 4 | January | 2016 | 313595 | 41582229 |
Now we will create a new column in our new dataframe that represents the percentage of total lightning strikes that occurred during each month for each year.
# Create new `percentage_lightning_per_month` column.
percentage_lightning['percentage_lightning_per_month'] = (percentage_lightning.number_of_strikes/
percentage_lightning.year_strikes * 100.0)
percentage_lightning.head()| month_txt | year | number_of_strikes | year_strikes | percentage_lightning_per_month | |
| 0 | April | 2016 | 2636427 | 41582229 | 6.340273 |
| 1 | August | 2016 | 7250442 | 41582229 | 17.436396 |
| 2 | December | 2016 | 316450 | 41582229 | 0.761022 |
| 3 | February | 2016 | 312676 | 41582229 | 0.751946 |
| 4 | January | 2016 | 313595 | 41582229 | 0.754156 |
Now we can plot the percentages by month in a bar graph.
plt.figure(figsize=(10,6))
month_order = ['January', 'February', 'March', 'April', 'May', 'June',
'July', 'August', 'September', 'October', 'November', 'December']
sns.barplot(
data = percentage_lightning,
x = 'month_txt',
y = 'percentage_lightning_per_month',
hue = 'year',
order = month_order )
plt.xlabel("Month")
plt.ylabel("% of lightning strikes")
plt.title("% of lightning strikes each Month (2016-2018)")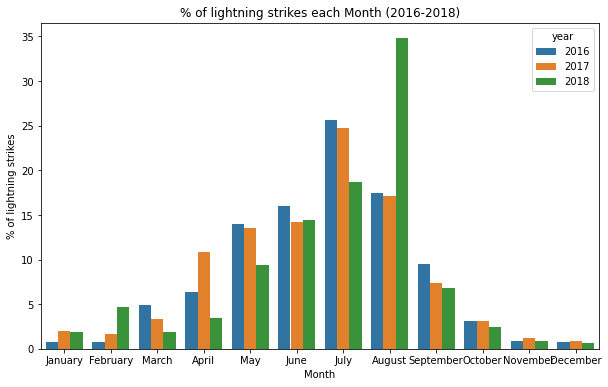
For all three years, there is a clear pattern over the course of each year. One month stands out: August. More than one third of the lightning strikes in 2018 happened in August.
The next step for a data professional trying to understand these findings might be to research storm and hurricane data, to learn whether those factors contributed to a greater number of lightning strikes for this particular month.