So far, we’ve constructed confidence intervals for large sample sizes, which are usually defined as sample sizes of 30 or more items. But sometimes there is not enough time, money, or resources to take a large sample, we may end up working with a small sample.
Large versus small sample sizes
Large sample: Z-scores
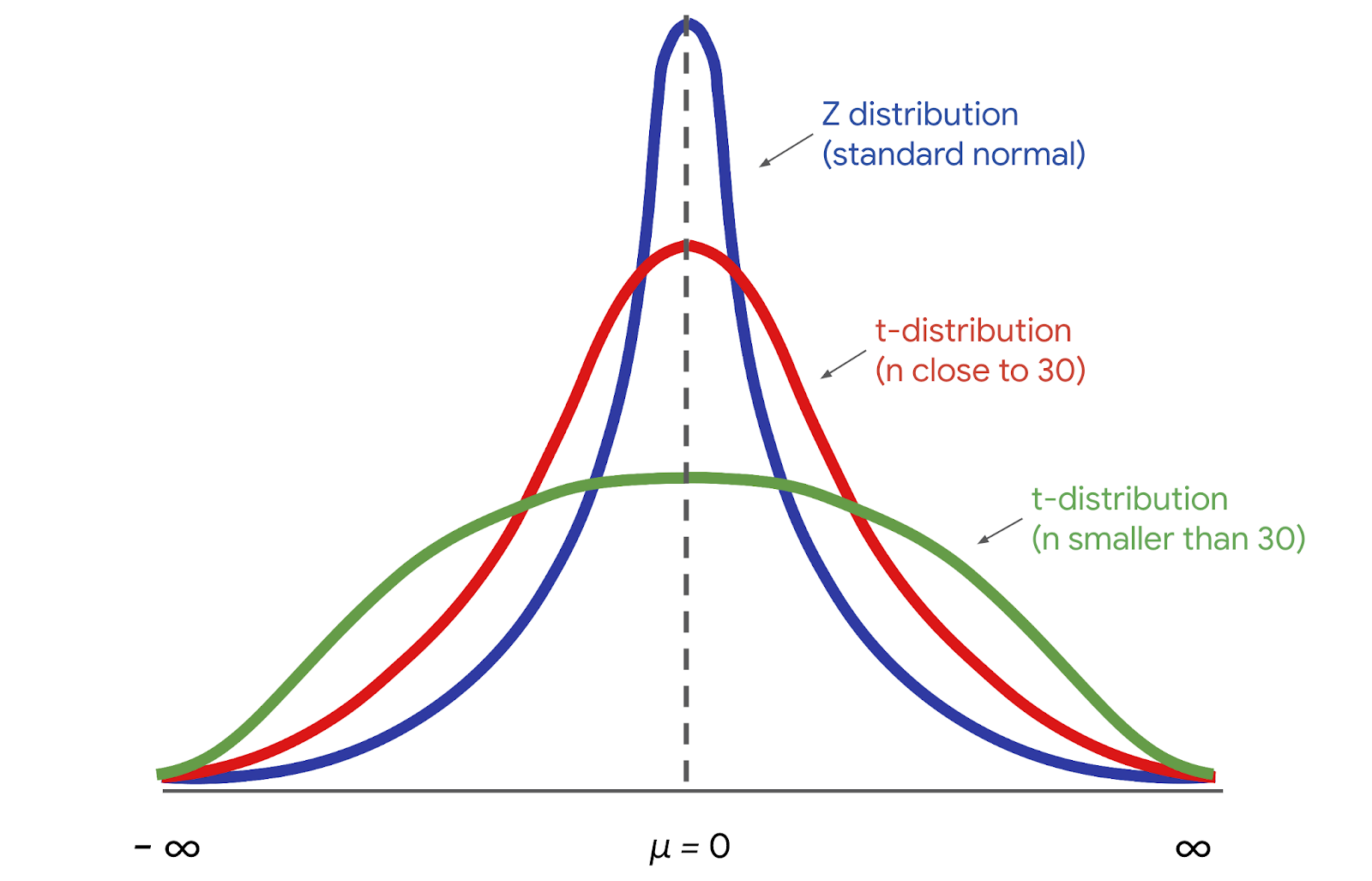
For large sample sizes, we use z-scores to calculate the margin of error. This is because of the central limit theorem: for large sample sizes, the sample mean is approximately normally distributed. For a standard normal distribution, also called a z-distribution, we use z-scores to make calculations about our data.
Small sample: T-scores
For small sample sizes, we need to use a different distribution, called the t-distribution. This is because there is more uncertainty involved in estimating the standard error for small sample sizes. If we’re working with a small sample size, and our data is approximately normally distributed, we should use the t-distribution rather than the standard normal distribution. For a t-distribution, we use t-scores to make calculations about our data.
The graph of the t-distribution has a bell shape that is similar to the standard normal distribution. But, the t-distribution has bigger tails than the standard normal distribution does. The bigger tails indicate the higher frequency of outliers that come with a small dataset. As the sample size increases, the t-distribution approaches the normal distribution. When the sample size reaches 30, the distributions are practically the same, and we can use the normal distribution for our calculations.
Example: Mean emission levels
Now let’s construct a confidence interval for a small sample size.
Context
Imagine we’re a data professional working for an auto manufacturer. The company produces high performance cars that are sold around the world. Typically, the engines in these cars have high emission rates of carbon dioxide, or CO2, which is a greenhouse gas that contributes to global warming. The engineering team has designed a new engine to reduce emissions for the company’s best-selling car.
Goal
The goal is to keep emissions below 460 grams of CO2 per mile. This will ensure the car meets emissions standards in every country it’s sold in. Plus, the lower emissions rate is good for the environment, which will appeal to new customers.
Ask
The engineering team asks us to provide a reliable estimate of the emissions rate for the new engine. Due to production issues, there are only a limited number of engines available for testing. So, we’ll be working with a small sample size.
Sample
The engineering team tests a random sample of 15 engines and collects data on their emissions. The mean emission rate is 430 grams of CO2 per mile, and the standard deviation is 35 grams of CO2 per mile.
Our single sample may not provide the actual mean emissions rate for every engine. The population mean for emissions could be above or below 430 grams of CO2 per mile.
Even though we only have a small sample of engines, we can construct a confidence interval that likely includes the actual emission rate for a large population of engines. This will give our manager a better idea of the uncertainty in our estimate. It will also help the engineering team decide if they need to do more work on the engine to lower the emissions rate.
Construct the confidence interval
Let’s review the steps for constructing a confidence interval:
- Identify a sample statistic.
- Choose a confidence level.
- Find the margin of error.
- Calculate the interval.
Step 1: Identify a sample statistic
Our sample represents the average emissions rate for 15 engines. We’re working with a sample mean.
Step 2: Choose a confidence level
The engineering team requests that we choose a 95% confidence level.
Step 3: Find the margin of error
For a small sample size, we calculate the margin of error by multiplying the t-score by the standard error.
The t-distribution is defined by a parameter called the degree of freedom. In our context, the degree of freedom is the sample size – 1, or 15-1 = 14. Given our degree of freedom and our confidence level, we can use a programming language like Python or other statistical software to calculate our t-score.
Based on a degree of freedom of 14, and a confidence level of 95%, our t-score is 2.145.
Now we can calculate the standard error, which measures the variability of our sample statistic. Here’s the formula for the standard error of the mean that we’ve used before:
Standard Error (Means)
SE(x) = s / √(n)
(s refers to sample standard deviation, n refers to sample size)
Our sample standard deviation is 35, and our sample size is 15. The calculation gives us a standard error of about 9.04.
The margin of error is our t-score multiplied by our standard error. This is 2.145 * 9.04 = 19.39.
Step 4: Calculate the interval
The upper limit of our interval is the sample mean plus the margin of error.
This is 430 + 19.39 = 449.39 grams of CO2 per mile.
The lower limit is the sample mean minus the margin of error.
This is 430 − 19.39 = 410.61 grams of CO2 per mile.
We have a 95% confidence interval that stretches from 410.61 grams of CO2 per mile to 449.39 grams of CO2 per mile.
95 CI [410.61, 449.39]
The confidence interval gives the engineering team important information. The upper limit of our interval is below the target of 460 grams of CO2 per mile. This result provides solid statistical evidence that the emissions rate for the new engine will meet emissions standards.
Note: Confidence intervals for small sample sizes only deal with population means, and not population proportions. The statistical reason for this distinction is rather technical, that is beyond my knowledge for now.
Disclaimer: Like most of my posts, this content is intended solely for educational purposes and was created primarily for my personal reference. At times, I may rephrase original texts, and in some cases, I include materials such as graphs, equations, and datasets directly from their original sources.
I typically reference a variety of sources and update my posts whenever new or related information becomes available. For this particular post, the primary source was Google Advanced Data Analytics Professional Certificate.