As a reminder; Descriptive statistics like the mean and standard deviation summarize the main features of the dataset. Inferential statistics use sample data to draw conclusions or make predictions about a larger population.
Here I’ll write about the inferential statistics and explore the relationship between sample and population in more detail.
Sampling is the process of selecting a subset of data from a population.
Some questions answered by sampling might be:
- How many products in an app store do we need to test to feel confident that all the products are secure from malware?
- How do we select a sample of users to run an effective A/B test for an online retail store?
- How do we select a sample of customers of a video streaming service to get reliable feedback on the shows they watch?
Representative sample – accurately reflects the characteristics of a population.
To make valid inferences or accurate predictions about a population, our sample should be representative of the population as a whole.
Important: A good model can’t overcome a bad sample.
The sampling process
- Identify the target population.
- Select the sampling frame.
- Choose the sampling method.
- Determine the sample size.
- Collect the sample data.
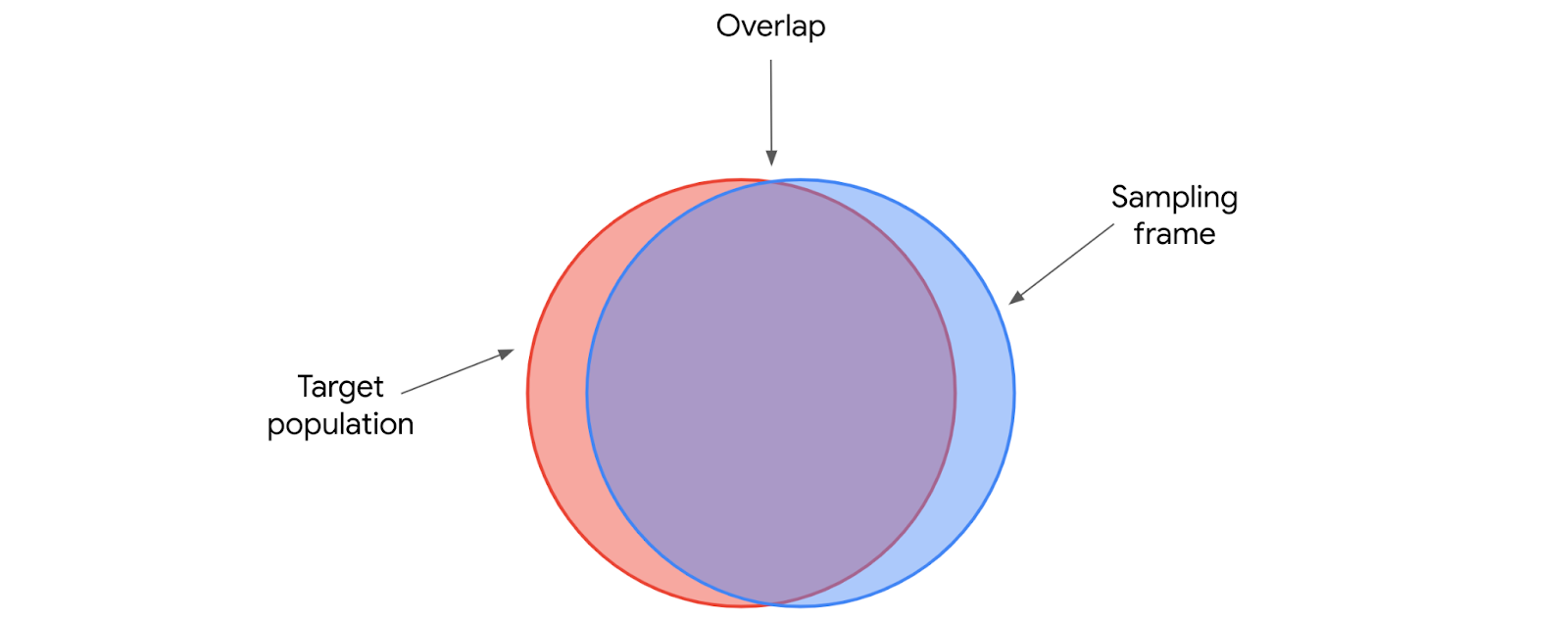
Target population and sampling frame
The target population is the complete set of elements that we’re interested in knowing more about. A sampling frame is a list of all the items in our target population.
Target population is general, sampling frame is specific.
So if our target population is 100,000 city residents who are 18 years or older and eligible to vote, our sampling frame could be a list of names for all these residents.
Ideally, our sampling frame should include the entire target population. However, for practical reasons, our sampling frame may not accurately match our target population because we may not have access to every member of the population. For instance, the city may not have reliable contact information about each resident, or perhaps not all eligible voters are actually registered to vote, so their opinions about the potential subway system aren’t relevant, since the project will be decided by an election.
For reasons like these, our sampling frame will not exactly overlap with our target population. Our sampling frame will include the list of residents 18 or over that we’re able to obtain useful information about. So the sampling frame is the accessible part of our target population.
Sampling methods
One way to help ensure that ‘our sample is representative’ is to choose the right sampling method.
There are two main types of sampling methods:
- Probability sampling uses random selection to generate a sample.
- Non-probability sampling is often based on convenience or the personal preferences (of the researcher rather than random selection).
Because probability sampling methods are based on random selection, every person in the population has an equal chance of being included in the sample. This gives us the best chance to get a representative sample, as our results are more likely to accurately reflect the overall population.
Sample size and sample data
Sample size refers to the number of individuals or items chosen for a study or experiment.
The sample size we choose depends on various factors, including the sampling method, the size and complexity of the target population, the limits of our resources, our timeline, and the goal of our research.
And the final step is to collect the sample data.
Probability sampling methods
- Simple random sampling
- Stratified random sampling
- Cluster random sampling
- Systematic random sampling
Simple random sample
In a simple random sample, every member of a population is selected randomly and has an equal chance of being chosen.
Main benefits of simple random sample:
- Usually fairly representative
- Tend to avoid bias
However, in practice, it’s often expensive and time-consuming to conduct large, simple random samples.
Stratified random sample
In a stratified random sample, we divide a population into groups and randomly select some members from each group to be in the sample. These groups are called strata. Strata can be organized by age, gender, income, or whatever category we’re interested in studying.
Stratified random samples help ensure that:
- Members from each group in the population are included in the survey.
However, one main disadvantage of stratified sampling is that it can be difficult to identify appropriate strata for a study if we lack knowledge of a population. For example, if we want to study median income among a population, we may want to stratify our sample by job type, or industry, or location, or education level. If we don’t know how relevant these categories are to median income, it will be difficult to choose the best one for our study.
Cluster random sample
When we’re conducting a cluster random sample, we divide a population into clusters, randomly select certain clusters, and include all members from the chosen clusters in the sample.
Clusters are divided using identifying details, such as age, gender, location, or whatever we want to study.
One advantage of this method is that a cluster sample gets every member from a particular cluster, which is useful when each cluster reflects the population as a whole. This method is helpful:
- When dealing with large and diverse populations that have clearly defined subgroups.
However, a main disadvantage of cluster sampling is that it may be difficult to create clusters that accurately reflect the overall population. For example, for practical reasons, we may only have access to the offices in the United States when our company has locations all over the world.
Systematic random sample
In a systematic random sample, we put every member of a population into an ordered sequence. Then we choose a random starting point in the sequence and select members for our sample at regular intervals.
Systematic random samples are:
- Often representative of the population (since every member has an equal chance of being included in the sample).
- Also quick and convenient (when we have a complete list of the members of our population).
However, one disadvantage of systematic sampling is that we need to know the size of the population that we want to study before we begin. If we don’t have this information, it’s difficult to choose consistent intervals. Plus, if there’s a hidden pattern in the sequence, we might not get a representative sample. For example, if every 10th name on our list happens to be an honor student, we may only get feedback on the study habits of honor students and not all students.
These four methods of probability sampling (simple, stratified, cluster, and systematic), are all based on random selection, which is the preferred method of sampling for most data professionals. These methods can help us create a sample that is representative of the population.
Real-life examples of probability sampling methods
Some real-life samples could be like the following.
For simple random sampling:
Imagine we want to survey the employees of a company about their work experience. The company employs 10,000 people. We can assign each employee in the company database a number from 1 to 10,000, and then use a random number generator to select 100 people for our sample. In this scenario, each of the employees has an equal chance of being chosen for the sample.
For stratified sampling:
Imagine we’re doing market research for a new product, and we want to analyze the preferences of consumers in different age groups. We might divide our target population into strata according to age: 20-29, 30-39, 40-49, 50-59, etc. Then, we can survey an equal number of people from each age group, and draw conclusions about the consumer preferences of each age group. Our results will help marketers decide which age groups to focus on to optimize sales for the new product.
For cluster random sampling:
Imagine we want to conduct an employee satisfaction survey at a global restaurant franchise using cluster sampling. The franchise has 40 restaurants around the world. Each restaurant has about the same number of employees in similar job roles. We randomly select 4 restaurants as clusters. We include all the employees at the 4 restaurants in our sample.
For systematic random sampling:
Imagine we want to survey students at a high school about their study habits. For a systematic random sample, we’d put the students’ names in alphabetical order and randomly choose a starting point: say, number 4. Starting with number 4, we select every 10th name on the list (4, 14, 24, 34, … ), until we have a sample of 100 students.
Non-probability sampling methods
Non-probability sampling methods do not use random selection, so they do not typically generate representative samples. In fact, they often result in biased samples.
However, non-probability sampling is often less expensive and more convenient for researchers to conduct. Sometimes due to budget, time or other reasons, it’s just not possible to use probability sampling. Plus non-probability methods can be useful for exploratory studies which seek to develop an initial understanding of a population, not draw conclusions or make predictions about the population as a whole.
- Convenient sampling
- Voluntary response sampling
- Snowball sampling
- Purposive sampling
Convenient sampling
In convenient sampling, we choose members of a population that are easy to contact or reach. For example, to conduct an opinion poll, a researcher might stand in front of a local high school during the day and poll people that happened to walk by.
Because these symbols are based on convenience to the researcher and not a broader sample of the population, convenience samples often show under-coverage bias. Under-coverage bias occurs when some members of a population are inadequately represented in the sample. For instance, people who don’t work at or attend the school will not be represented as much in this sample.
Voluntary response sampling
Voluntary response sampling consists of members of a population who volunteer to participate in a study. For example, the owners of a restaurant want to know how people feel about their dinner options. They ask their regular customers to take an online survey about the quality of the restaurant’s food.
Voluntary response samples tend to suffer from nonresponse bias, which occurs when certain groups of people are less likely to provide responses. People who voluntarily respond will likely have stronger opinions, either positive or negative than the rest of the population. This makes the volunteer customers at the restaurant an unrepresentative sample.
Snowball sampling
In a snowball sample, researchers recruit initial participants to be in a study and then ask them to recruit other people to participate in the study.
For example, if a study was investigating cheating among college students, potential participants might not want to come forward. But if a researcher can find a couple of students willing to participate, these two students may know others who have also cheated on exams. The initial participants could then recruit others by sharing the benefits of the study and reassuring them of confidentiality.
However, this type of recruiting can lead to sampling bias. Because initial participants recruit additional participants on their own, it’s likely that most of them will share similar characteristics. These characteristics might be unrepresentative of the total population under study.
Purposive sampling
In purposive sampling researchers select participants based on the purpose of their study. Because participants are selected for the sample according to the needs of the study, applicants who do not fit the profiles are rejected.
For example, a researcher wants to survey students on the effectiveness of certain teaching methods at the university. The researcher only wants to include students who regularly attend class and have an established record of academic achievement. So they select the students with the highest grade point averages to participate in the study.
Purposive sampling, the researchers often intentionally exclude certain groups from the sample to focus on a specific group they think is most relevant to their study. In this case, the researcher excludes students who don’t have high grade point averages. This could lead to biased outcomes because the students in the sample are not likely to be representative of the overall student population.
Disclaimer: Like most of my posts, this content is intended solely for educational purposes and was created primarily for my personal reference. At times, I may rephrase original texts, and in some cases, I include materials such as graphs, equations, and datasets directly from their original sources.
I typically reference a variety of sources and update my posts whenever new or related information becomes available. For this particular post, the primary source was Google Advanced Data Analytics Professional Certificate.