Sampling distribution is a probability distribution of a sample statistic.
Sampling variability – how much an estimate varies between samples.
If our sample is large enough, our sample mean will roughly equal the population mean.
The more variability in our sample data, the less likely it is that the sample mean is an accurate estimate of the population mean. Data professionals use the standard deviation of the sample means to measure this variability.
Standard Error
In statistics, the standard deviation of a sample statistic is called the standard error. The standard error of the mean measures variability among all our sample means. A larger standard error indicates that the sample means are more spread out, whether there’s more variability.
Note that the concept of standard error is based on the practice of repeated sampling. In reality, researchers usually work with a single sample. It’s often too complicated, expensive, or time-consuming to take repeated samples of a population.
Instead, statisticians have derived a formula for calculating the standard error based on the mathematical assumption of repeated sampling.
Formula to calculate the standard error of the sample mean:
SEM = S / √n
S is the sample standard deviation and n is the sample size.
For example, imagine that a sample of 100 penguins has a mean weight of three pounds and a standard deviation of one pound. We can calculate the standard error by dividing the sample standard deviation (1) by the square root of the sample size (100), that equals 0.1.
This means that our best estimate for the true population mean weight of all penguins is 3 pounds, but we should expect that the mean weight from one sample to the next will vary with a standard deviation of about 0.1 pounds.
As sample size gets larger, standard error gets smaller. In general, we can have more confidence in our estimates as the sample size gets larger and the standard error gets smaller. This is because the mean of our sampling distribution gets closer to the population mean.
The central limit theorem
The central limit theorem can be used to estimate:
- The mean annual household income for an entire city or country
- The mean height and weight for an entire animal or plant population
- The mean commute time for all the employees of a large corporation.
The central limit theorem states that the sampling distribution of the mean approaches a normal distribution as the sample size increases. In other words, as our sample increases, our sampling distribution assumes the shape of a bell curve. If we take a large enough sample of the population, the sample mean will be roughly equal to the population mean.
There is no exact rule for how large a sample size needs to be in order for the central limit theorem to apply. In general, a sample size of 30 or more is considered sufficient.
Exploratory data analysis can help us determine how large of a sample is necessary for a given dataset. What’s really powerful about the central limit theorem is that it holds true for any population. We don’t need to know the shape of our population distribution in advance to apply the theorem.
In practice, this specific sample size we choose will depend on factors like budget, time, resources, and the desired level of confidence for our estimate. If we take a large enough sample from the population, the mean of our sampling distribution will equal the population mean.
Conditions
In order to apply the central limit theorem, the following conditions must be met:
- Randomization: Our sample data must be the result of random selection. Random selection means that every member in the population has an equal chance of being chosen for the sample.
- Independence: Our sample values must be independent of each other. Independence means that the value of one observation does not affect the value of another observation. Typically, if we know that the individuals or items in our dataset were selected randomly, we can also assume independence.
- 10%: To help ensure that the condition of independence is met, our sample size should be no larger than 10% of the total population when the sample is drawn without replacement (which is usually the case).
- Note: In general, we can sample with or without replacement. When a population element can be selected only one time, we are sampling without replacement. When a population element can be selected more than one time, we are sampling with replacement.
- 10%: To help ensure that the condition of independence is met, our sample size should be no larger than 10% of the total population when the sample is drawn without replacement (which is usually the case).
- Sample size: The sample size needs to be sufficiently large.
- Requirements for precision. The larger the sample size, the more closely our sampling distribution will resemble a normal distribution, and the more precise our estimate of the population mean will be.
- The shape of the population. If our population distribution is roughly bell-shaped and already resembles a normal distribution, the sampling distribution of the sample mean will be close to a normal distribution even with a small sample size.
In general, many statisticians and data professionals consider a sample size of 30 to be sufficient when the population distribution is roughly bell-shaped, or approximately normal. However, if the original population is not normal—for example, if it’s extremely skewed or has lots of outliers—data professionals often prefer the sample size to be a bit larger. Exploratory data analysis can help you determine how large of a sample is necessary for a given dataset.
The sampling distribution of the proportion
Population proportion refers to the percentage of individuals or elements in a population that share a certain characteristic.
The sampling distribution of the proportion can be used to estimate the proportion of
- All visitors to a website who make a purchase before leaving.
- Assembly line products that meet quality control standards
- Voters who support a candidate in an upcoming election.
Sampling distribution of the sample mean
A sampling distribution is a probability distribution of a sample statistic. Recall that a probability distribution represents the possible outcomes of a random variable, such as a coin toss or a die roll. In the same way, a sampling distribution represents the possible outcomes for a sample statistic.
Sample statistics are based on randomly sampled data, and their outcomes cannot be predicted with certainty. We can use a sampling distribution to represent statistics such as the mean, median, standard deviation, range, and more.
We can use a sampling distribution to represent the frequency of all our different sample means.
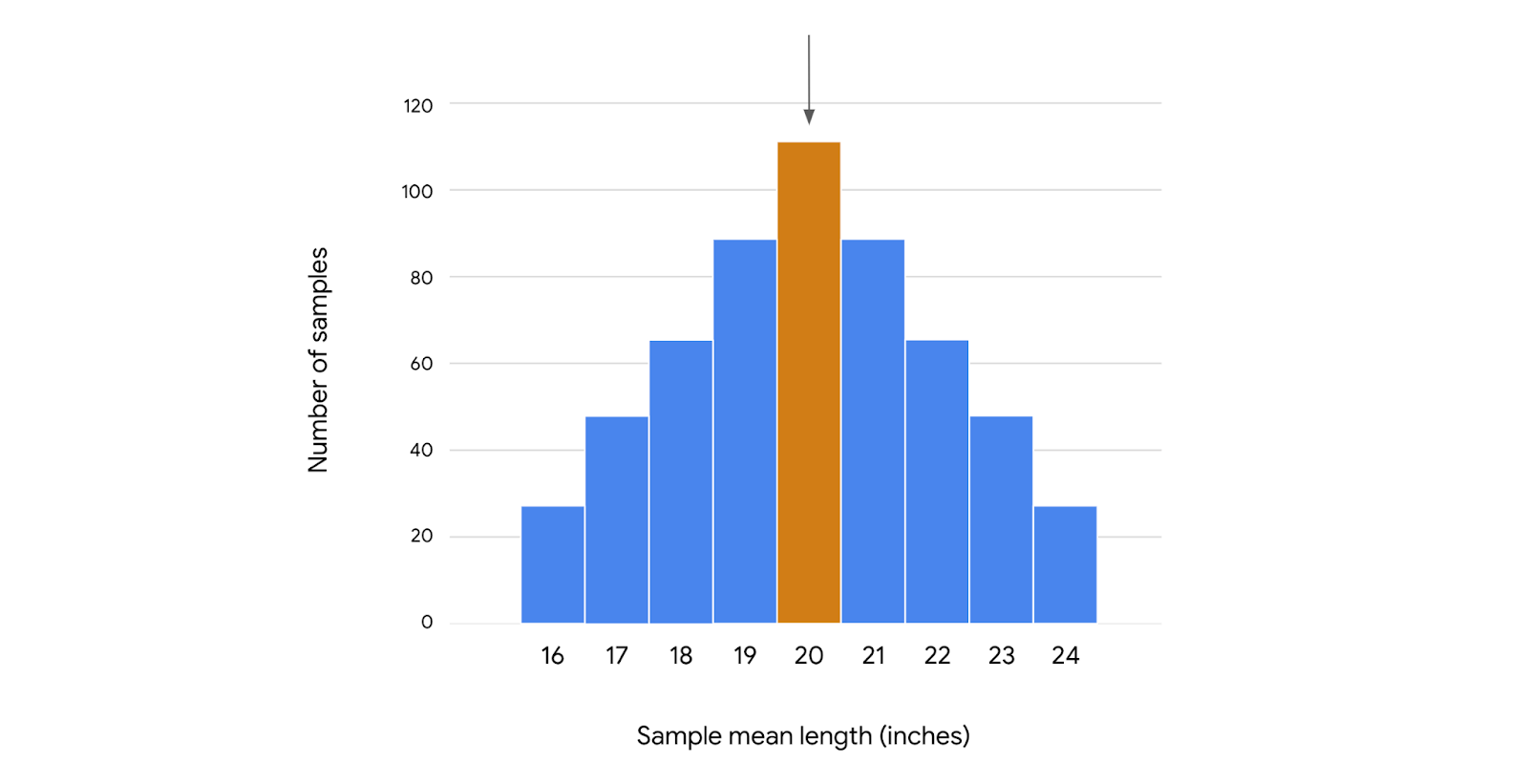
For example, if we take 10 simple random samples of 10 trout each from the population, we can show the sampling distribution of the mean as a histogram. The most frequently occurring value in our sample data will be around 20 inches. The values that occur least frequently will be the more extreme lengths, such as 16 inches or 24 inches.

As we increase the size of a sample, the mean length of our sample data will get closer to the mean length of the population. If we sampled the entire population—in other words, if we actually measured every single trout in the lake—our sample mean would be the same as the population mean. However, we don’t need to measure millions of fish to get an accurate estimate of the population mean. If we take a large enough sample size from the population, say 1000 trout, our sample mean will be a precise estimate of the population mean (20 inches).
The more variability in our sample data, the less likely it is that the sample proportion is an accurate estimate of the population proportion.
Standard error
We can also use our sample data to estimate how precisely the mean length of any given sample represents the population mean. This is useful to know because the sample mean varies from sample to sample, and any given sample mean is likely to differ from the true population mean.
Data professionals use the standard deviation of the sample means to measure this variability. In statistics, the standard deviation of a sample statistic is called the standard error. The standard error provides a numerical measure of sampling variability. The standard error of the mean measures variability among all our sample means.
A larger standard error indicates that the sample means are more spread out, or that there’s more variability. A smaller standard error indicates that the sample means are closer together, or that there’s less variability.
In practice, using a single sample of observations, we can apply the following formula to calculate the estimated standard error of the sample mean: s / √n. In the formula, s refers to the sample standard deviation, and n refers to the sample size.
For example, in our study of trout lengths, imagine that a sample of 100 trout has a mean length of 20 inches and a standard deviation of 2 inches. We can calculate the estimated standard error by dividing the sample standard deviation, 2, by the square root of the sample size, 100:
2 ÷ √100 = 2 ÷ 10 = 0.2
This means we should expect that the mean length from one sample to the next will vary with a standard deviation of about 0.2 inches.
We can use the following formula to calculate the standard error of the proportion:
SE(p̂) = sqrt(p̂ * (1-p̂) / n)
p̂ (p hat) refers to the population proportion, and n refers to the sample size.
(The “^” symbol is called a hat. This indicates that the proportion is based on sampled data, much like “x bar” denotes a sample mean.)
As our sample size gets larger, our standard error gets smaller. As our sample gets larger, our sample proportion gets closer to the true population proportion. The more accurate the estimate of the population proportion, the smaller the standard error.
Typically, the next step for a data professional would be to use the standard error to construct a confidence interval. This describes the uncertainty of our estimate and gives our stakeholders more detailed information about our results.
Disclaimer: Like most of my posts, this content is intended solely for educational purposes and was created primarily for my personal reference. At times, I may rephrase original texts, and in some cases, I include materials such as graphs, equations, and datasets directly from their original sources.
I typically reference a variety of sources and update my posts whenever new or related information becomes available. For this particular post, the primary source was Google Advanced Data Analytics Professional Certificate.