Categorical data
Data that is divided into a limited number of qualitative groups. For example, demographic information tends to be categorical, like occupation, ethnicity and educational attainment. It’s like data that uses words or qualities rather than numbers.
Many data models and algorithms don’t work as well with categorical data as they do with numerical data. Assigning numerical representative values to categorical data is often the quickest and most effective way to learn about the distribution of categorical values in a data set.
(There are some algorithms that work well with categorical variables in word form, like, decision trees. However, with many data sets, the categorical data will need to be turned into numerical data.)
There are several ways to change categorical data to numerical. We will focus on two common methods, creating dummy variables and label encoding.
Dummy variables
Variables with values of 0 or 1, which indicate the presence or absence of something. Dummy variables are especially useful in statistical models and machine learning algorithms.
Label encoding
Data transformation technique where each category is assigned a unique number instead of a qualitative value.
Data is much simpler to clean, join and group when it is all numbers, it also takes up less storage space. An algorithm or model typically runs smoother when we take the time to transform our categorical data into numerical data.
A sample for Label Encoding
Let’s bring back the NOAA’s lightning dataset.
Objective
We will be examining monthly lightning strike data collected by the National Oceanic and Atmospheric Association (NOAA) for 2016–2018. The dataset includes three columns: date, number_of_strikes, and center_point_geom.
The objective is to assign the monthly number of strikes to the following categories: mild, scattered, heavy, or severe. Then we will create a heatmap of the three years so we can get a high-level understanding of monthly lightning severity from a simple diagram.
Import libraries and read the data file
import datetime
import matplotlib.pyplot as plt
import pandas as pd
import seaborn as sns
df = pd.read_csv('eda_label_encoding_dataset.csv')
df.info()<class 'pandas.core.frame.DataFrame'>
RangeIndex: 10479003 entries, 0 to 10479002
Data columns (total 3 columns):
# Column Dtype
--- ------ -----
0 date object
1 number_of_strikes int64
2 center_point_geom object
dtypes: int64(1), object(2)
memory usage: 239.8+ MB
Prepare the data to work with date
First, let’s convert the date column to datetime, as we did a couple of times before.
# Convert `date` column to datetime
df['date'] = pd.to_datetime(df['date'])
# Create new `month` column
df['month'] = df['date'].dt.month_name().str.slice(stop=3)
df.head()| date | number_of_strikes | center_point_geom | month | |
| 0 | 2016-08-05 | 16 | POINT(-101.5 24.7) | Aug |
| 1 | 2016-08-05 | 16 | POINT(-85 34.3) | Aug |
| 2 | 2016-08-05 | 16 | POINT(-89 41.4) | Aug |
| 3 | 2016-08-05 | 16 | POINT(-89.8 30.7) | Aug |
| 4 | 2016-08-05 | 16 | POINT(-86.2 37.9) | Aug |
Now we need to encode the months as categorical information. This allows us to specifically designate them as categories that adhere to a specific order, which is helpful when we plot them later. We’ll also create a new year column. Then we’ll group the data by year and month, sum the remaining columns, and assign the results to a new dataframe.
# Create categorical designations
months = ['Jan', 'Feb', 'Mar', 'Apr', 'May', 'Jun', 'Jul', 'Aug', 'Sep', 'Oct', 'Nov', 'Dec']
# Encode `month` column as categoricals
df['month'] = pd.Categorical(df['month'], categories=months, ordered=True)
# Create `year` column by extracting the year info from the datetime object
df['year'] = df['date'].dt.strftime('%Y')
# Create a new df of month, year, total strikes
df_by_month = df.groupby(['year', 'month']).sum(numeric_only=True).reset_index()
df_by_month.head()
# NOTE: In pandas v.2.X+ we must set 'numeric_only=True' or else the sum() function will throw an error| year | month | number_of_strikes | |
| 0 | 2016 | Jan | 313595 |
| 1 | 2016 | Feb | 312676 |
| 2 | 2016 | Mar | 2057527 |
| 3 | 2016 | Apr | 2636427 |
| 4 | 2016 | May | 5800500 |
Create a categorical variable
We’ll create a new column called strike_level that contains a categorical variable representing the lightning strikes for each month as mild, scattered, heavy, or severe. The pd.qcut pandas function makes this easy. We just input the column to be categorized, the number of quantiles to sort the data into, and how we want to name each quantile.
# Create a new column that categorizes number_of_strikes into 1 of 4 categories
df_by_month['strike_level'] = pd.qcut(
df_by_month['number_of_strikes'],
4,
labels = ['Mild', 'Scattered', 'Heavy', 'Severe'])
df_by_month.head()| year | month | number_of_strikes | strike_level | |
| 0 | 2016 | Jan | 313595 | Mild |
| 1 | 2016 | Feb | 312676 | Mild |
| 2 | 2016 | Mar | 2057527 | Scattered |
| 3 | 2016 | Apr | 2636427 | Heavy |
| 4 | 2016 | May | 5800500 | Severe |
Encode strike_level into numerical values
Now that we have a categorical strike_level column, we can extract a numerical code from it using cat.codes (a function that takes categories and assigns them a numeric code) and assign this number to a new column.
# Create new column representing numerical value of strike level
df_by_month['strike_level_code'] = df_by_month['strike_level'].cat.codes
df_by_month.head()| year | month | number_of_strikes | strike_level | strike_level_code | |
| 0 | 2016 | Jan | 313595 | Mild | 0 |
| 1 | 2016 | Feb | 312676 | Mild | 0 |
| 2 | 2016 | Mar | 2057527 | Scattered | 1 |
| 3 | 2016 | Apr | 2636427 | Heavy | 2 |
| 4 | 2016 | May | 5800500 | Severe | 3 |
Creating dummy variables (demonstrational)
We can also create binary “dummy” variables from the strike_level column. This is a useful tool if we’d like to pass the categorical variable into a model. To do this, we could use the function pd.get_dummies().
pd.get_dummies(df_by_month['strike_level'])| Mild | Scattered | Heavy | Severe | |
| 0 | 1 | 0 | 0 | 0 |
| 1 | 1 | 0 | 0 | 0 |
| 2 | 0 | 1 | 0 | 0 |
| 3 | 0 | 0 | 1 | 0 |
| 4 | 0 | 0 | 0 | 1 |
| 5 | 0 | 0 | 0 | 1 |
| 6 | 0 | 0 | 0 | 1 |
| 7 | 0 | 0 | 0 | 1 |
| 8 | 0 | 0 | 1 | 0 |
| 9 | 0 | 1 | 0 | 0 |
| 10 | 1 | 0 | 0 | 0 |
| 11 | 1 | 0 | 0 | 0 |
| 12 | 0 | 1 | 0 | 0 |
| 13 | 1 | 0 | 0 | 0 |
| 14 | 0 | 1 | 0 | 0 |
| 15 | 0 | 0 | 1 | 0 |
| 16 | 0 | 0 | 1 | 0 |
| 17 | 0 | 0 | 1 | 0 |
| 18 | 0 | 0 | 0 | 1 |
| 19 | 0 | 0 | 0 | 1 |
| 20 | 0 | 0 | 1 | 0 |
| 21 | 0 | 1 | 0 | 0 |
| 22 | 1 | 0 | 0 | 0 |
| 23 | 1 | 0 | 0 | 0 |
| 24 | 0 | 1 | 0 | 0 |
| 25 | 0 | 0 | 1 | 0 |
| 26 | 0 | 1 | 0 | 0 |
| 27 | 0 | 1 | 0 | 0 |
| 28 | 0 | 0 | 1 | 0 |
| 29 | 0 | 0 | 0 | 1 |
| 30 | 0 | 0 | 0 | 1 |
| 31 | 0 | 0 | 0 | 1 |
| 32 | 0 | 0 | 1 | 0 |
| 33 | 0 | 1 | 0 | 0 |
| 34 | 1 | 0 | 0 | 0 |
| 35 | 1 | 0 | 0 | 0 |
Simply calling the function as we did above will not convert the data unless we reassign the result back to a dataframe.
pd.get_dummies(df[‘column’]) 🠚 df unchanged
df = pd.get_dummies(df[‘column’]) 🠚 df changed
We don’t need to create dummy variables for our heatmap, so let’s continue without converting the dataframe.
Create a heatmap of number of strikes per month
Let’s discover what we can potentially learn from these groupings above. To do that, we’ll plot our data.
We want our heatmap to have the months on the x-axis and the years on the y-axis, and the color gradient should represent the severity (mild, scattered, heavy, severe) of lightning for each month. A simple way of preparing the data for the heatmap is to pivot it so the rows are years, columns are months, and the values are the numeric code of the lightning severity. We can do this with the df.pivot() method.
# Create new df that pivots the data
df_by_month_plot = df_by_month.pivot(index='year', columns='month', values='strike_level_code')
df_by_month_plot.head()| month | Jan | Feb | Mar | Apr | May | Jun | Jul | Aug | Sep | Oct | Nov | Dec |
| year | ||||||||||||
| 2016 | 0 | 0 | 1 | 2 | 3 | 3 | 3 | 3 | 2 | 1 | 0 | 0 |
| 2017 | 1 | 0 | 1 | 2 | 2 | 2 | 3 | 3 | 2 | 1 | 0 | 0 |
| 2018 | 1 | 2 | 1 | 1 | 2 | 3 | 3 | 3 | 2 | 1 | 0 | 0 |
ax = sns.heatmap(df_by_month_plot, cmap = 'Blues')
colorbar = ax.collections[0].colorbar
colorbar.set_ticks([0, 1, 2, 3])
colorbar.set_ticklabels(['Mild', 'Scattered', 'Heavy', 'Severe'])
plt.show()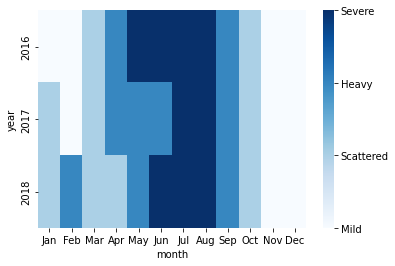
The heatmap indicates that for all three years, the most lightning strikes occurred during the summer months. A heatmap is an easily digestible way to understand a lot of data in a single graphic.
To give more information about the code above:
- cmap definition gives us a preset color gradient from dark blue to white.
- Then we used the standard collection zero from seaborn for our color bar. This just gives us a preset gradient color bar, which saves us a lot of time from having to code our own colors on a color bar.
- Next, we set the color bar ticks to zero through three and label those ticks according to our four strike levels, severe, heavy, scattered, and mild.
Some potential problems with label encoding
Imagine we’re analyzing a dataset with categories of music genres. We label encode “Blues,” “Electronic Dance Music (EDM),” “Hip Hop,” “Jazz,” “K-Pop,” “Metal,” “ and “Rock,” with the following numeric values, “1, 2, 3, 4, 5, 6, and 7.”
- With this label encoding, the resulting machine learning model could derive not only a ranking, but also a closer connection between Blues (1) and EDM (2) because of how close they are numerically than, say, Blues(1) and Jazz(4).
- In addition to these presumed relationships (which we may or may not want in your analysis) we should also notice that each code is equidistant from the other in the numeric sequence, as in 1 to 2 is the same distance as 5 to 6, etc.
- The question is, does that equidistant relationship accurately represent the relationships between the music genres in our dataset?
- To ask another question, after encoding, will the visualization or model we build treat the encoded labels as a ranking?
In summary, label encoding may introduce unintended relationships between the categorical data in our dataset. There is another method for categorical encoding that may help with these potential problems.
One-hot Encoding
As I mentioned at the beginning, we can also create dummy variables. This creation of dummies is called one-hot encoding. A table with one-hot encoding could be like this:
| N/A | Mild | Scattered | Heavy | Severe |
| 0 | 1 | 0 | 0 | 0 |
| 1 | 1 | 0 | 0 | 0 |
| 2 | 0 | 1 | 0 | 0 |
| 3 | 0 | 0 | 1 | 0 |
| 4 | 0 | 0 | 0 | 1 |
| 5 | 0 | 0 | 0 | 1 |
| 6 | 0 | 0 | 0 | 1 |
| 7 | 0 | 0 | 0 | 1 |
Label encoding or one-hot encoding: Which one to choose?
There is no simple answer to whether we should use label encoding or one-hot encoding. The decision needs to be made on a case-by-case, or dataset-by-dataset basis. But here are some guidelines:
We can use label encoding when:
- There are a large number of different categorical variables, because label encoding uses far less data than one-hot encoding.
- The categorical values have a particular order to them (for example, age groups can be grouped as youngest to oldest or oldest to youngest).
- We plan to use a decision tree or random forest machine learning model.
We can use one-hot encoding when:
- There is a relatively small amount of categorical variables, because one-hot encoding uses much more data than label encoding.
- The categorical variables have no particular order.
- We use a machine learning model in combination with dimensionality reduction, like Principal Component Analysis (PCA).