There are many different ways to validate a set of data, but here we’ll work on Input validation.
Input validation
The practice of thoroughly analyzing and double checking to make sure data is complete, error free, and high quality.
Objective
We will be examining monthly lightning strike data collected by the National Oceanic and Atmospheric Association (NOAA) for 2018. The dataset includes five columns: date, number_of_strikes, center_point_geom, longitude, and latitude.
The objective is to inspect the data and validate the quality of its contents. We will check for:
- Null values
- Missing dates
- A plausible range of daily lightning strikes in a location
- A geographical range that aligns with expectation
Imports, Read, and Basic Check
import matplotlib.pyplot as plt
import pandas as pd
import plotly.express as px
import seaborn as sns
df = pd.read_csv('eda_input_validation_joining_dataset1.csv')
df.head()| date | number_of_strikes | center_point_geom | longitude | latitude | |
| 0 | 2018-01-03 | 194 | POINT(-75 27) | -75.0 | 27.0 |
| 1 | 2018-01-03 | 41 | POINT(-78.4 29) | -78.4 | 29.0 |
| 2 | 2018-01-03 | 33 | POINT(-73.9 27) | -73.9 | 27.0 |
| 3 | 2018-01-03 | 38 | POINT(-73.8 27) | -73.8 | 27.0 |
| 4 | 2018-01-03 | 92 | POINT(-79 28) | -79.0 | 28.0 |
# Display the data types of the columns
print(df.dtypes)date object
number_of_strikes int64
center_point_geom object
longitude float64
latitude float64
dtype: object
As we did many times before, let’s change the date column into a datetime.
# Convert `date` column to datetime
df['date'] = pd.to_datetime(df['date'])Let’s begin our data validation by counting the number of missing values in each column first.
df.isnull().sum()date 0
number_of_strikes 0
center_point_geom 0
longitude 0
latitude 0
dtype: int64
Now let’s check ranges for all variables.
df.describe(include = 'all')| date | number_of_strikes | center_point_geom | longitude | latitude | |
| count | 3401012 | 3.401012e+06 | 3401012 | 3.401012e+06 | 3.401012e+06 |
| unique | 357 | NaN | 170855 | NaN | NaN |
| top | 2018-09-01 00:00:00 | NaN | POINT(-81.5 22.5) | NaN | NaN |
| freq | 31773 | NaN | 108 | NaN | NaN |
| first | 2018-01-01 00:00:00 | NaN | NaN | NaN | NaN |
| last | 2018-12-31 00:00:00 | NaN | NaN | NaN | NaN |
| mean | NaN | 1.311403e+01 | NaN | -9.081778e+01 | 3.374688e+01 |
| std | NaN | 3.212099e+01 | NaN | 1.296593e+01 | 7.838555e+00 |
| min | NaN | 1.000000e+00 | NaN | -1.418000e+02 | 1.660000e+01 |
| 25% | NaN | 2.000000e+00 | NaN | -1.008000e+02 | 2.760000e+01 |
| 50% | NaN | 4.000000e+00 | NaN | -9.070000e+01 | 3.350000e+01 |
| 75% | NaN | 1.200000e+01 | NaN | -8.130000e+01 | 3.970000e+01 |
| max | NaN | 2.211000e+03 | NaN | -4.320000e+01 | 5.170000e+01 |
Notice that the number of unique dates in the date column is 357. This means that eight days of 2018 are missing from the data, because 2018 had 365 days.
Validate date column
Let’s confirm each day is listed by designing a calendar index, we’ll call it full date range. This is how we will determine which dates are missing.
# Create datetime index of every date in 2018
full_date_range = pd.date_range(start='2018-01-01', end='2018-12-31')
# Determine which values are in `full_date_range` but not in `df['date']`
full_date_range.difference(df['date'])DatetimeIndex(['2018-06-19', '2018-06-20', '2018-06-21', '2018-06-22',
'2018-09-18', '2018-09-19', '2018-12-01', '2018-12-02'],
dtype='datetime64[ns]', freq=None)
There are four consecutive days missing in June of 2018, then two consecutive days in September, and two consecutive days in December. This finding would be something to investigate or to question the owner of the data, to find out the reason why.
Given that the number of missing days is relatively small, we can complete our analysis by making a note of the missing days in the presentation. This will ensure that anyone who analyzes our visualization or presentation will know that the data depicted doesn’t include those missing dates.
Validate number_of_strikes column
Let’s make a boxplot to better understand the range of values in the data.
sns.boxplot(y = df['number_of_strikes'])<matplotlib.axes._subplots.AxesSubplot at 0x7f2062f56ed0>
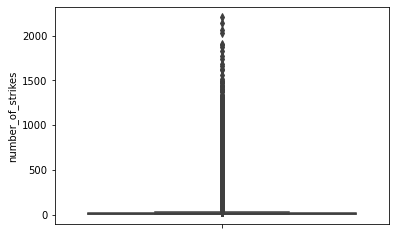
It looks like the distribution is very skewed. Most days of the year have less than five lightning strikes, but some days have more than 2,000. But we can remove the outliers from the boxplot visualization to help us understand where the majority of our data is distributed.
sns.boxplot(y = df['number_of_strikes'], showfliers=False)<matplotlib.axes._subplots.AxesSubplot at 0x7f20542926d0>
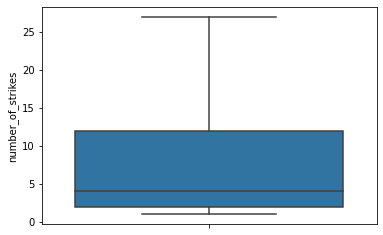
The interquartile range is approximately 2–12 strikes. But we know from the previous boxplot that there are many outlier days that have hundreds or even thousands of strikes. This exercise just helped us make sure that most of the dates in our data had plausible values for the number of strikes.
If the highest distribution of strikes were all in the 2000s, we might be a little more skeptical.
Validate latitude and longitude columns
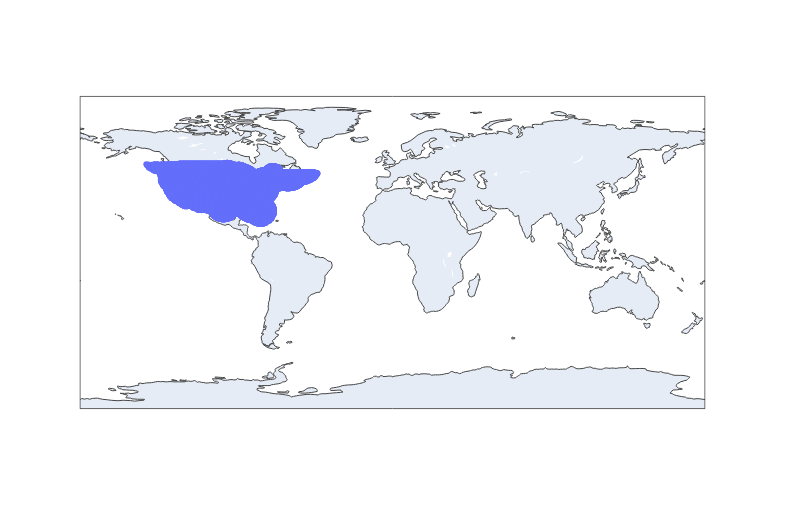
Finally, let’s verify that all of the latitudes and longitudes included in this dataset are in the United States. We’ll plot the points on a map to make sure the points in the data are relevant and not in unexpected locations.
Because this can be a computationally intensive process, we’ll prevent redundant computation by dropping rows that have the same values in their latitude and longitude columns. We can do this because the purpose here is to examine locations that had lightning strikes, but it doesn’t matter how many strikes they had or when.
# Create new df only of unique latitude and longitude combinations
df_points = df[['latitude', 'longitude']].drop_duplicates()
df_points.head()| latitude | longitude | |
| 0 | 27.0 | -75.0 |
| 1 | 29.0 | -78.4 |
| 2 | 27.0 | -73.9 |
| 3 | 27.0 | -73.8 |
| 4 | 28.0 | -79.0 |
When we’re working with hundreds of thousands of data points plotted on a map, it takes a lot of computing power. To make it a shorter runtime, below we’ll use the Plotly express package. The package is designed to keep runtimes as low as possible.
p = px.scatter_geo(df_points, lat = 'latitude', lon = 'longitude')
p.show()